
在我們的數字世界中,企業每天處理大量數據。 數據使組織保持運轉並幫助其做出更明智的決策。 企業中充斥著大量文檔,從員工創建新文檔到從各種來源(如電子郵件、門戶、發票、收據、申請、提案、索賠等)進入組織的文檔。
除非有人審查這些文檔,否則無法了解特定文檔的內容或處理它的最佳方式。 然而,手動處理每個文檔以了解應該將其存儲在何處以及如何存儲是很困難的。
讓我們探索文檔分類,了解為什麼文檔分類對企業至關重要,並研究計算機視覺、自然語言處理和光學字符識別如何在文檔分類或文檔處理中發揮作用。
什麼是文件分類?
手動文檔分類任務可能是許多企業的巨大瓶頸,因為它們耗時、容易出錯且耗費資源。 當使用基於 NLP 和 ML 的自動分類模型時,文檔中的文本將被自動識別、標記和分類。
文檔分類任務通常基於兩種分類:文本和視覺。 文本分類基於內容的流派、主題或類型。 自然語言處理用於理解文本的概念、情感和上下文。 視覺分類是基於文檔中存在的視覺結構元素使用計算機視覺和圖像識別系統完成的。
為什麼企業需要文件分類?

每個企業,無論大小,都必須處理文檔以管理其日常運營。 由於無法手動處理每個文件,因此有必要採用自動文件分類系統。 文檔分類系統允許企業組織內容並使其隨時可用。
文檔分類在從醫院到企業的各個行業都有多個用例。
- 它幫助企業自動化文檔管理和處理。
- 文檔分類是一項單調且重複的任務,自動化流程可減少處理錯誤並縮短周轉時間。
- 文檔自動化還可以提高效率、可靠性和可擴展性。
文檔分類與。 文本分類
文本分類和文檔分類有時可以互換使用。 儘管兩者之間存在細微差別,但重要的是要了解它們之間的區別。
文字分類 是關於使用技術來分析基於文本的文檔中的文本。 文本可以分為不同的級別,例如
| 句子水平 | 分句級別 |
|---|---|
| 文本分類基於單個句子中的信息。 | 子句級別從句子中提取子表達式。 |
| 段落級別 | 文檔級別 |
|---|---|
| 從單個段落中提取核心或最關鍵的信息。 | 從整個文檔中提取重要信息。 |
文本分類是文檔分類的一個子集,它完全處理對任何給定文檔中的文本進行分類。 雖然文本分類只處理文本, 文件分類 既是文字的又是視覺的。 在文本分類中,僅使用文本進行分類,而在文檔分類中,完整的文檔可用於上下文。
文檔分類如何工作?
文檔分類可以使用兩種方法完成:手動和自動。 在手動分類中,人類用戶必須查看文檔,找到概念之間的關係,並進行相應的分類。 在自動文檔分類中,使用了機器學習和深度學習技術。 讓我們通過了解業務流程中不同類型的文檔來闡明文檔分類方法。
結構化文件
文檔包含具有一致編號和字體的格式良好的數據。 文檔的排版也是一致的,沒有偏差。 為此類結構化文檔構建分類工具既簡單又可預測。
非結構化文件
非結構化文檔的內容以非結構化或開放格式呈現。 示例包括信件、合同和訂單。 由於它們不一致,因此定位關鍵信息變得具有挑戰性。

文檔分類技術?
自動文檔分類使用機器學習和自然語言處理技術來簡化、自動化和加速分類過程。 機器學習使文檔分類變得不那麼麻煩、更快、更準確、可擴展且沒有偏見。
文檔分類可以使用三種技術來完成。 他們是
基於規則的技術
基於規則的技術基於為模型提供指令的語言模式和規則。 這些模型經過訓練可以識別語言模式、形態、句法、語義等來標記文本。 這種技術可以不斷改進,添加新規則並即興創作以提取準確的見解。 然而,這種技術可能非常耗時、不可擴展且複雜。
監督學習
在監督學習中定義了一組標籤,並手動標記了幾個文本,以便機器學習系統可以學習做出準確的預測。 該算法是在一組標記文檔上手動訓練的。 您輸入系統的數據越多,結果就越好。 例如,如果文字說“服務價格合理”,則標籤應位於“定價”之下。 模型訓練完成後,它可以自動預測未見過的文檔。
無監督學習
在無監督學習中,相似的文檔被分組到不同的集群中。 這種學習不需要任何先驗知識。 這些文檔根據字體、主題、模板等進行分類。 如果規則是預定義的、調整的和完善的,這個模型可以提供準確的分類。
文件分類過程
構建自動文檔分類算法涉及深度學習和機器學習工作流程。
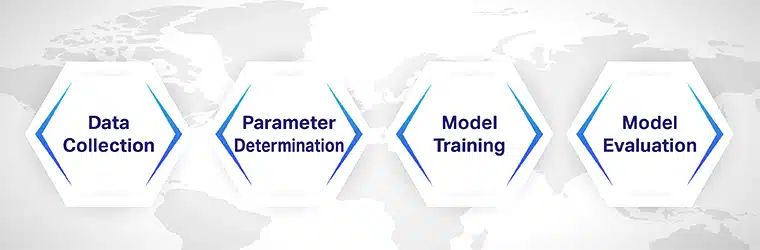
第 1 步:數據收集
數據採集 可能是訓練文檔分類算法中最關鍵的一步。 有必要收集各種類別的文檔,以便算法可以學習如何對它們進行分類。
例如,如果您的模型需要分為五個不同的類別,則您的數據集必須至少包含每個類別 300 個文檔。
此外,請確保您用於訓練的數據集已正確標記。 如果數據集不正確,您構建的模型將充滿問題。
第二步:參數確定
在訓練模型之前,您必須確定用於訓練機器學習模型的參數。 可以修改您在此階段定義的指標,使模型的預測更加準確可靠。
第三步:模型訓練
設置參數後,必須對模型進行訓練。 如果您剛剛開始模型開發,您可以嘗試使用開源數據集進行訓練和測試。
如果模型通常使用機器學習算法,您可以導入模型或根據算法的邏輯執行編碼。
第 4 步:模型評估
在訓練後評估模型對於提高其有效性和準確性至關重要。 首先將數據集分為兩個主要部分,一個用於訓練,另一個用於測試。 使用 70% 的數據集來訓練模型,其餘的 30% 用於測試和評估。
現實生活中的用例
文檔分類被用來解決幾個業務問題。 雖然大多數用例不是分類任務,但該算法發現自己被用來解決幾個現實生活中的問題。
垃圾郵件檢測
文檔分類,尤其是文本分類,用於檢測不需要的垃圾郵件。 該模型經過訓練以檢測垃圾郵件短語及其頻率,以確定郵件是否為垃圾郵件。 例如,Google 的 Gmail 垃圾郵件檢測器使用自然語言處理技術來檢測垃圾郵件中頻繁出現的單詞,並將郵件放入正確的文件夾中。
情緒分析
通過社交聆聽進行的情緒分析有助於企業了解他們的客戶、他們的意見和評論。 通過對評論、反饋和投訴進行分類並根據它們的情感性質對其進行分類,基於 NLP 的模型有助於進行情感分析。 該模型經過訓練以提取表示或具有正面或負面含義的詞。
機票或優先級分類
任何企業的客戶服務部門都會遇到許多服務請求和票據。 自動文檔分類工具可以幫助處理大量票證。 使用 NLP,可以將優先票路由到正確的部門。 這顯著提高了解析、處理和服務的速度。
物體識別
自動文檔分類還用於通過根據類別對文檔進行分類來處理文檔中的大量視覺數據。 對象識別通常用於電子商務或製造單位以對產品進行分類。
開始使用由 AI 提供支持的文檔分類
文檔包含對業務運作至關重要的數據。 這些文檔包含有價值的見解,可進一步推進組織的運營、服務和增長目標。
然而,對文檔進行分類是一項繁瑣而又必要的工作。 由於文檔分類是一個挑戰,尤其是在體積比較大的情況下,有必要有一個自動化的文檔分類系統。
由機器學習算法訓練的基於 AI 的文檔分類模型高效、經濟、無錯誤且準確。 但是,只有當您正在構建的模型在質量和準確標記的數據集上進行訓練時,該過程才能開始。
夏普為您帶來 預先標記的數據集 有助於開發準確的分類模型。 與我們聯繫,立即開始使用您的文檔分類工具。


