
人工智能和大數據有可能找到全球問題的解決方案,同時優先考慮當地問題並以許多深刻的方式改變世界。 AI 為所有人帶來解決方案——在所有環境中,從家庭到工作場所。 人工智能計算機,與 機器學習 培訓,可以以自動化但個性化的方式模擬智能行為和對話。
然而,人工智能面臨著包容性問題,而且往往存在偏見。 幸運的是,專注於 人工智能倫理 通過多樣化的訓練數據消除無意識的偏見,可以在多元化和包容性方面帶來新的可能性。
人工智能訓練數據多樣性的重要性
 訓練數據的多樣性和質量是相關的,因為兩者相互影響並影響 AI 解決方案的結果。 人工智能解決方案的成功取決於 多樣化的數據 它受過訓練。 數據多樣性可防止 AI 過度擬合——這意味著模型僅執行或從用於訓練的數據中學習。 由於過度擬合,AI 模型無法在對訓練中未使用的數據進行測試時提供結果。
訓練數據的多樣性和質量是相關的,因為兩者相互影響並影響 AI 解決方案的結果。 人工智能解決方案的成功取決於 多樣化的數據 它受過訓練。 數據多樣性可防止 AI 過度擬合——這意味著模型僅執行或從用於訓練的數據中學習。 由於過度擬合,AI 模型無法在對訓練中未使用的數據進行測試時提供結果。
人工智能培訓的現狀 數據
數據中的不平等或缺乏多樣性會導致不公平、不道德和非包容性的人工智能解決方案,從而加深歧視。 但是,數據多樣性如何以及為何與 AI 解決方案相關?
所有類別的不平等代表會導致面部識別錯誤——一個重要的例子是谷歌照片,它將一對黑人夫婦歸類為“大猩猩”。 Meta 會提示正在觀看黑人視頻的用戶是否願意“繼續觀看靈長類動物的視頻”。
例如,對少數民族的分類不准確或不當,尤其是在聊天機器人中,可能會導致人工智能訓練系統出現偏見。 根據2019年的報告 歧視系統——人工智能中的性別、種族、權力, 超過 80% 的 AI 教師是男性; FB 上的女性 AI 研究人員僅佔谷歌的 15% 和 10%。
多樣化訓練數據對 AI 性能的影響
 從數據表示中遺漏特定的群體和社區可能會導致算法出現偏差。
從數據表示中遺漏特定的群體和社區可能會導致算法出現偏差。
數據偏差經常被意外地引入數據系統——通過對某些種族或群體的抽樣不足。 當面部識別系統在不同的面孔上進行訓練時,它可以幫助模型識別特定特徵,例如面部器官的位置和顏色變化。
標籤頻率不平衡的另一個結果是,系統可能會在加壓以在短時間內產生輸出時將少數視為異常。
實現人工智能訓練數據的多樣性
另一方面,生成多樣化的數據集也是一個挑戰。 某些類別的數據完全缺乏可能導致代表性不足。 它可以通過讓人工智能開發團隊在技能、種族、種族、性別、紀律等方面更加多樣化來緩解。 此外,解決人工智能中數據多樣性問題的理想方法是從一開始就面對它,而不是試圖修復已經完成的事情——在數據收集和管理階段注入多樣性。
不管圍繞人工智能的炒作如何,它仍然取決於人類收集、選擇和訓練的數據。 人類天生的偏見會反映在他們收集的數據中,這種無意識的偏見也會蔓延到 ML 模型中。
收集和整理各種訓練數據的步驟
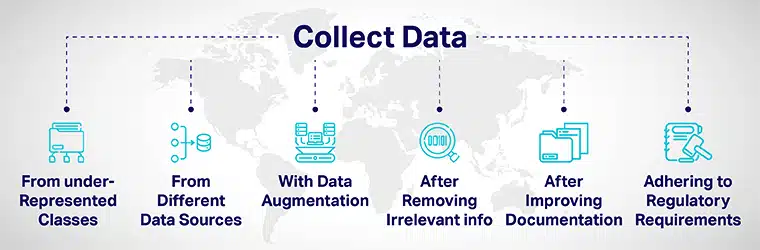
數據多樣性 可以通過以下方式實現:
- 深思熟慮地從代表性不足的類中添加更多數據,並將您的模型暴露給不同的數據點。
- 通過從不同的數據源收集數據。
- 通過數據擴充或人為操作數據集來增加/包含與原始數據點明顯不同的新數據點。
- 在為 AI 開發過程僱用申請人時,從申請中刪除所有與工作無關的信息。
- 通過改進模型開發和評估的文檔來提高透明度和問責制。
- 引入法規以建立多樣性和 人工智能的包容性 來自基層的製度。 各國政府制定了指導方針,以確保多樣性並減輕可能帶來不公平結果的人工智能偏見。
[另請閱讀: 了解有關 AI 訓練數據收集過程的更多信息 ]
結論
目前,只有少數大型科技公司和學習中心專門參與開發人工智能解決方案。 這些精英空間充斥著排斥、歧視和偏見。 然而,這些是正在開發人工智能的空間,這些先進人工智能係統背後的邏輯充滿了代表性不足的群體所承受的同樣的偏見、歧視和排斥。
在討論多樣性和非歧視時,重要的是要質疑其受益的人和受其傷害的人。 我們還應該看看它讓誰處於劣勢——通過強加“正常”人的想法,人工智能可能會讓“其他人”處於危險之中。
在不承認權力關係、公平和正義的情況下討論 AI 數據的多樣性不會展示更大的圖景。 為了充分了解人工智能訓練數據的多樣性範圍以及人類和人工智能如何共同緩解這場危機, 聯繫 Shaip 的工程師. 我們擁有多元化的 AI 工程師,可以為您的 AI 解決方案提供動態和多樣化的數據。


