
人工智能、大數據和機器學習繼續影響著世界各地的政策制定者、企業、科學、媒體機構和各種行業。 報告顯示,全球人工智能的採用率目前處於 在35 2022% – 比 4 年增長 2021%。 據報導,另有 42% 的公司正在探索人工智能為其業務帶來的諸多好處。
為許多人工智能計劃提供動力和 機器學習 解決方案是數據。 AI 只能和提供給算法的數據一樣好。 低質量的數據可能導致低質量的結果和不准確的預測。
雖然人們對 ML 和 AI 解決方案的開發給予了很多關注,但缺乏對什麼是高質量數據集的認識。 在這篇文章中,我們瀏覽時間軸 高質量的人工智能訓練數據 並通過對數據收集和培訓的理解來確定人工智能的未來。
AI訓練數據的定義
在構建 ML 解決方案時,訓練數據集的數量和質量很重要。 機器學習系統不僅需要大量動態、無偏見且有價值的訓練數據,而且還需要大量數據。
但什麼是 AI 訓練數據?
AI 訓練數據是標記數據的集合,用於訓練 ML 算法以做出準確的預測。 機器學習系統嘗試識別和識別模式,理解參數之間的關係,做出必要的決定,並根據訓練數據進行評估。
以自動駕駛汽車為例。 自動駕駛 ML 模型的訓練數據集應包括汽車、行人、路牌和其他車輛的標記圖像和視頻。
簡而言之,要提高 ML 算法的質量,您需要大量結構良好、帶註釋和標記的訓練數據。
高質量訓練數據的重要性及其演變
高質量的訓練數據是 AI 和 ML 應用程序開發的關鍵輸入。 數據是從各種來源收集的,並以不適合機器學習目的的無組織形式呈現。 高質量的訓練數據——標記、註解和標記——始終採用有組織的格式——非常適合 ML 訓練。
高質量的訓練數據使 ML 系統更容易識別對象並根據預定特徵對其進行分類。 如果分類不准確,數據集可能會產生不良模型結果。
人工智能訓練數據的早期
儘管 AI 主導了當前的商業和研究領域,但在 ML 主導之前的早期 人工智能 完全不同。
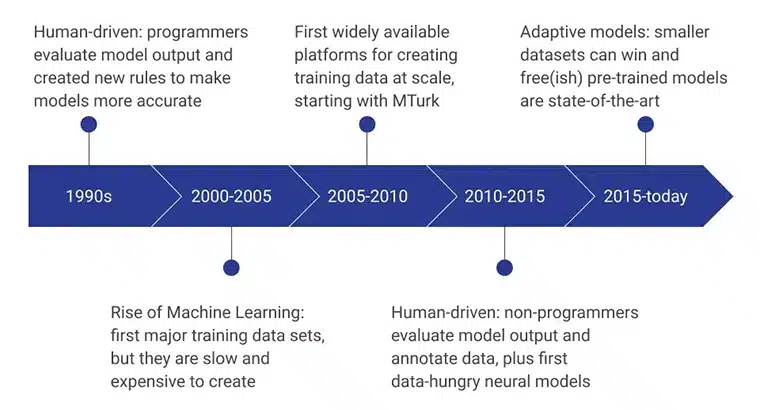
AI 訓練數據的初始階段由人類程序員提供支持,他們通過不斷設計使模型更高效的新規則來評估模型輸出。 在 2000 年至 2005 年期間,創建了第一個主要數據集,這是一個極其緩慢、依賴資源且成本高昂的過程。 它導致訓練數據集被大規模開發,亞馬遜的 MTurk 在改變人們對數據收集的看法方面發揮了重要作用。 同時,人工標註和註釋也開始興起。
接下來幾年的重點是非程序員創建和評估數據模型。 目前,重點是使用高級訓練數據收集方法開發的預訓練模型。
數量超過質量
過去評估 AI 訓練數據集的完整性時,數據科學家專注於 AI訓練數據量 超過質量。
例如,人們普遍錯誤地認為大型數據庫會提供準確的結果。 龐大的數據量被認為是數據價值的良好指標。 數量只是決定數據集價值的主要因素之一——數據質量的作用得到了認可。
意識到 數據質量 取決於數據的完整性、可靠性、有效性、可用性和及時性。 最重要的是,項目的數據適用性決定了所收集數據的質量。
由於訓練數據不佳導致早期人工智能係統的局限性
訓練數據不佳,加上缺乏先進的計算系統,是早期人工智能係統的幾個未實現承諾的原因之一。
由於缺乏高質量的訓練數據,ML 解決方案無法準確識別視覺模式,阻礙了神經研究的發展。 儘管許多研究人員確定了口語識別的前景,但由於缺乏語音數據集,語音識別工具的研究或開發未能取得成果。 開發高端人工智能工具的另一個主要障礙是計算機缺乏計算和存儲能力。
向高質量訓練數據的轉變
人們對數據集質量很重要的認識發生了顯著轉變。 機器學習系統要準確模仿人類智能和決策能力,就必須依賴大量、高質量的訓練數據。
將您的 ML 數據視為一項調查——數據越大 數據樣本 尺寸越大,預測越好。 如果樣本數據不包括所有變量,它可能無法識別模式或得出不准確的結論。
人工智能技術的進步和對更好訓練數據的需求
 人工智能技術的進步增加了對高質量訓練數據的需求。
人工智能技術的進步增加了對高質量訓練數據的需求。更好的訓練數據增加了可靠 ML 模型的機會的理解產生了更好的數據收集、註釋和標記方法。 數據的質量和相關性直接影響人工智能模型的質量。
 人工智能技術的進步增加了對高質量訓練數據的需求。
人工智能技術的進步增加了對高質量訓練數據的需求。更加關注數據質量和準確性
為了讓 ML 模型開始提供準確的結果,它以經過迭代數據提煉步驟的高質量數據集為基礎。
例如,通過圖片、視頻或親身接觸,人類可能會在幾天內認出特定品種的狗。 人類從他們的經驗和相關信息中汲取靈感,以記住並在必要時提取這些知識。 然而,它對機器來說並不那麼容易。 必須向機器提供該特定品種和其他品種的帶有清晰註釋和標籤的圖像(數百或數千),才能建立聯繫。
AI 模型通過將訓練的信息與模型中呈現的信息相關聯來預測結果 真實世界. 如果訓練數據不包含相關信息,則該算法將變得無用。
多樣化和有代表性的訓練數據的重要性
數據多樣性的增加也提高了能力,減少了偏見,並促進了所有場景的公平代表性。 如果 AI 模型是使用同質數據集訓練的,則可以確保新應用程序僅適用於特定目的並服務於特定人群。數據集可能偏向於特定的人口、種族、性別、選擇和知識觀點,這可能會導致模型不准確。
重要的是要確保整個數據收集流程,包括選擇主題池、管理、註釋和標籤,充分多樣化、平衡並代表人群。
 數據多樣性的增加也提高了能力,減少了偏見,並促進了所有場景的公平代表性。 如果 AI 模型是使用同質數據集訓練的,則可以確保新應用程序僅適用於特定目的並服務於特定人群。
數據多樣性的增加也提高了能力,減少了偏見,並促進了所有場景的公平代表性。 如果 AI 模型是使用同質數據集訓練的,則可以確保新應用程序僅適用於特定目的並服務於特定人群。人工智能訓練數據的未來
AI 模型未來的成功取決於用於訓練 ML 算法的訓練數據的質量和數量。 重要的是要認識到數據質量和數量之間的這種關係是特定於任務的並且沒有明確的答案。
最終,訓練數據集的充分性取決於它是否有能力為構建的目的可靠地良好運行。
數據收集和註釋技術的進步
由於 ML 對輸入的數據很敏感,因此簡化數據收集和註釋策略至關重要。 數據收集、管理、虛假陳述、不完整的測量、不准確的內容、數據重複和錯誤的測量中的錯誤都會導致數據質量不足。
通過數據挖掘、網絡抓取和數據提取的自動化數據收集為更快的數據生成鋪平了道路。 此外,預先打包的數據集可作為一種快速修復數據收集技術。
眾包是另一種開創性的數據收集方法。 雖然無法保證數據的準確性,但它是收集公眾形象的絕佳工具。 最後,專 數據收集 專家還提供用於特定目的的數據來源。
更加重視訓練數據中的倫理考慮
隨著人工智能的快速發展,出現了一些倫理問題,尤其是在訓練數據收集方面。 訓練數據收集中的一些倫理考慮包括知情同意、透明度、偏見和數據隱私。由於數據現在包括面部圖像、指紋、錄音和其他關鍵生物識別數據等所有內容,因此確保遵守法律和道德規範以避免代價高昂的訴訟和聲譽受損變得至關重要。
未來有可能獲得更高質量和多樣化的培訓數據
有巨大的潛力 優質多樣的訓練數據 將來。 由於對數據質量的認識以及滿足 AI 解決方案質量需求的數據提供商的可用性。
目前的數據提供者擅長使用突破性的技術以合乎道德和合法的方式獲取大量不同的數據集。 他們還有內部團隊來標記、註釋和呈現為不同 ML 項目定制的數據。
 隨著人工智能的快速發展,出現了一些倫理問題,尤其是在訓練數據收集方面。 訓練數據收集中的一些倫理考慮包括知情同意、透明度、偏見和數據隱私。
隨著人工智能的快速發展,出現了一些倫理問題,尤其是在訓練數據收集方面。 訓練數據收集中的一些倫理考慮包括知情同意、透明度、偏見和數據隱私。結論
與對數據和質量有深刻理解的可靠供應商合作非常重要 開發高端人工智能模型. Shaip 是首屈一指的註釋公司,擅長提供滿足您的 AI 項目需求和目標的定制數據解決方案。 與我們合作,探索我們帶來的能力、承諾和協作。


