
大型語言模型最近在其高度勝任的用例 ChatGPT 一夜成名後獲得了廣泛關注。 看到 ChatGPT 和其他聊天機器人的成功,許多人和組織開始對探索為此類軟件提供支持的技術產生興趣。
大型語言模型是該軟件背後的支柱,它支持各種自然語言處理應用程序的工作,如機器翻譯、語音識別、問答和文本摘要。 讓我們更多地了解 LLM 以及如何優化它以獲得最佳結果。
什麼是大型語言模型或 ChatGPT?
大型語言模型是一種機器學習模型,它利用人工神經網絡和大量數據孤島來為 NLP 應用程序提供動力。 在對大量數據進行訓練後,LLM 獲得了捕捉自然語言各種複雜性的能力,它進一步用於:
- 新文本的生成
- 文章和段落的總結
- 數據提取
- 重寫或解釋文本
- 數據分類
LLM 的一些流行示例是 BERT、Chat GPT-3 和 XLNet。 這些模型經過數億文本的訓練,可以為所有類型的不同用戶查詢提供有價值的解決方案。
大型語言模型的流行用例
以下是 LLM 的一些頂級和最普遍的用例:
文本生成
大型語言模型利用人工智能和計算語言學知識,自動生成自然語言文本,完成各種交際用戶需求,如寫文章、唱歌,甚至與用戶聊天。
機器翻譯
LLM 也可用於在任何兩種語言之間翻譯文本。 這些模型利用循環神經網絡等深度學習算法來學習源語言和目標語言的語言結構。 因此,它們用於將源文本翻譯成目標語言。
內容創作
現在,LLM 使機器能夠創建連貫且合乎邏輯的內容,這些內容可用於生成博客文章、文章和其他形式的內容。 這些模型利用其廣泛的深度學習知識,以獨特且可讀的格式為用戶理解和構建內容。
情緒分析
這是大型語言模型的一個令人興奮的用例,其中訓練模型以識別和分類標記文本中的情緒狀態和情緒。 該軟件可以檢測積極、消極、中立和其他復雜情緒等情緒,有助於深入了解客戶對不同產品和服務的意見和評論。
文本的理解、總結和分類
LLMs 為 AI 軟件提供了一個實用的框架來理解文本及其上下文。 通過訓練模型理解和分析大量數據,LLM 使 AI 模型能夠理解、總結甚至對不同形式和模式的文本進行分類。
問題回答
大型語言模型使 QA 系統能夠準確檢測和響應用戶的自然語言查詢。 此用例最流行的應用程序之一是 ChatGPT 和 BERT,它們分析查詢的上下文並通過大量文本進行搜索以找到用戶查詢的相關答案。
[另請閱讀: 語言處理的未來:大型語言模型和示例 ]

LLM 成功的 3 個基本條件
必須準確滿足以下三個條件才能提高效率並使您的大型語言模型成功:
存在用於模型訓練的大量數據
LLM 需要大量數據來訓練提供高效和最佳結果的模型。 有一些特定的方法,例如遷移學習和自我監督的預訓練,LLM 可以利用這些方法來提高其性能和準確性。
構建神經元層以促進模型的複雜模式
大型語言模型必須包含經過專門訓練以理解數據中復雜模式的神經元的各個層。 較淺層的神經元可以更好地理解複雜的模式。 該模型可以學習單詞之間的關聯、一起出現的主題以及詞性之間的關係。
針對用戶特定任務優化 LLM
可以通過更改層數、神經元和激活函數來針對特定任務調整 LLM。 例如,預測句子中以下單詞的模型通常比設計用於從頭生成新句子的模型使用更少的層和神經元。
大型語言模型的流行示例
以下是在不同垂直行業中廣泛使用的 LLM 的幾個突出示例:
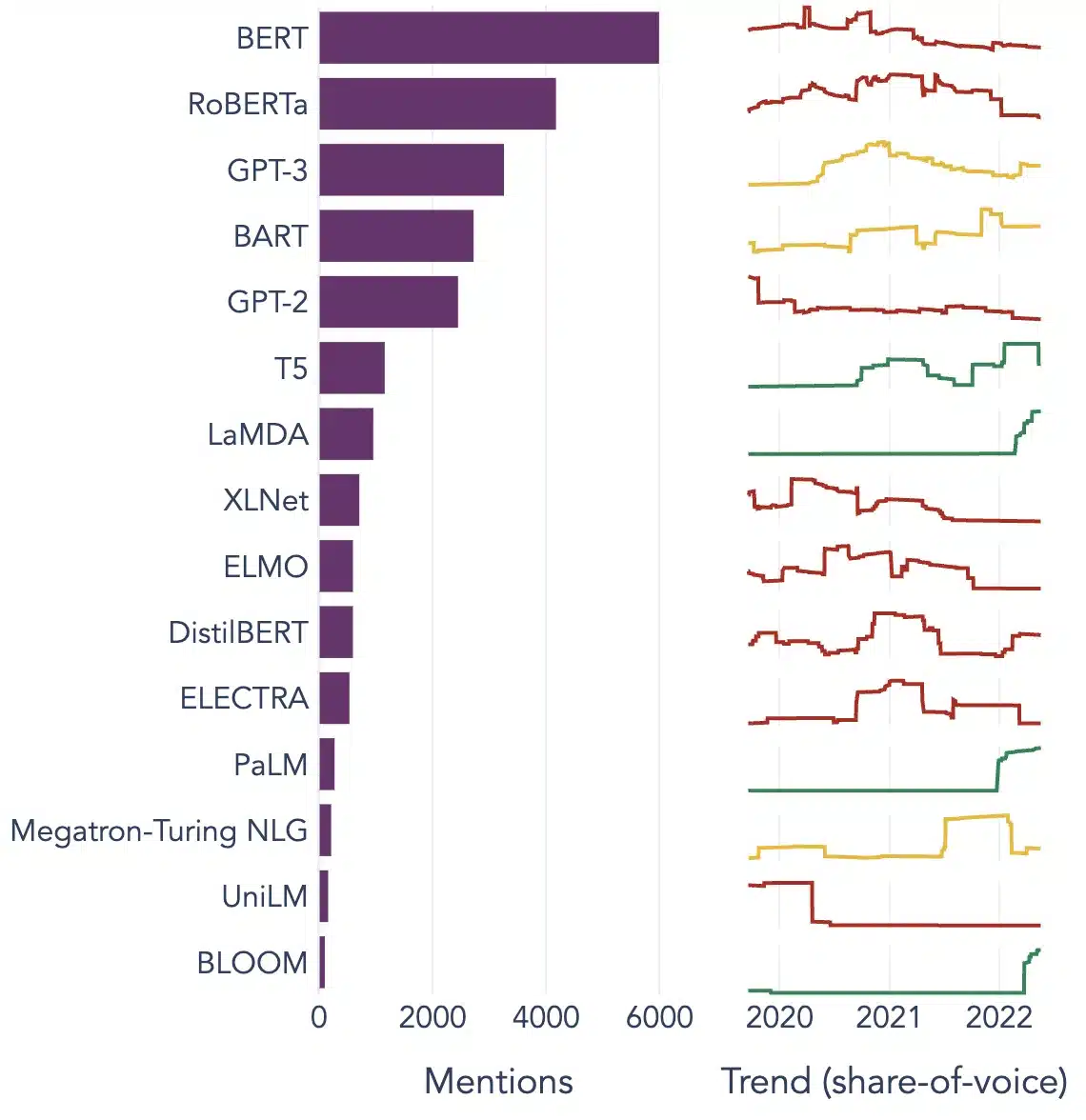
圖片來源: 邁向數據科學
結論
法學碩士看到了通過提供強大而準確的語言理解能力和解決方案來提供無縫用戶體驗來徹底改變 NLP 的潛力。 然而,為了提高 LLM 的效率,開發人員必須利用高質量的語音數據來生成更準確的結果並生成高效的 AI 模型。
Shaip 是領先的 AI 技術解決方案之一,可提供 50 多種語言和多種格式的廣泛語音數據。 了解有關 LLM 的更多信息,並從 今天的 Shaip 專家.


