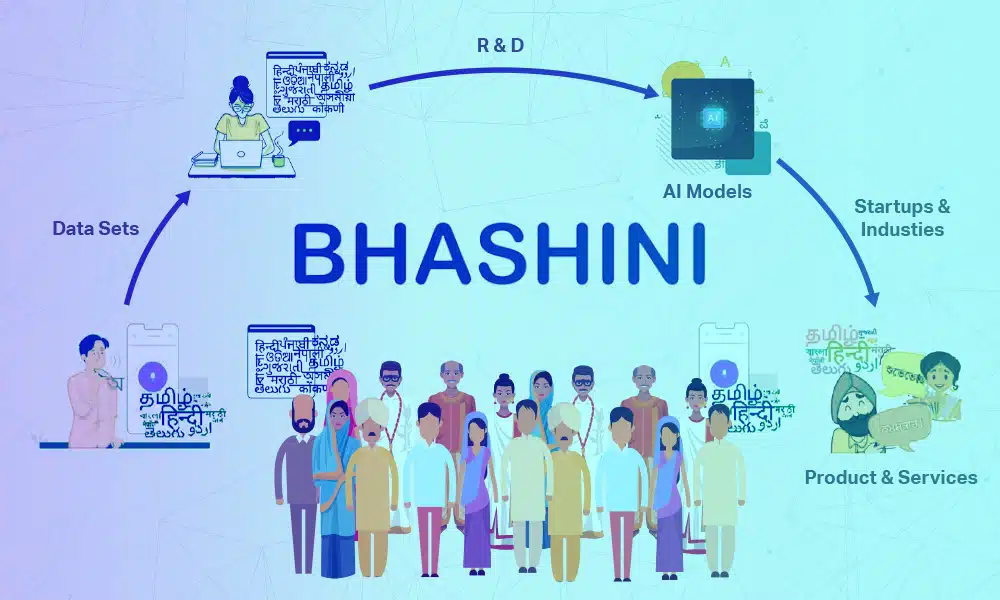
如果您在日常生活中使用 Siri、Alexa、Cortana、Amazon Echo 或其他設備,您會接受 語音識別 已經成為我們生活中無處不在的一部分。 這些 人工智能驅動 語音助手將用戶的口頭查詢轉換為文本,解釋並理解用戶所說的內容,從而做出適當的回應。
需要高質量的數據收集來開發可靠的語音識別模型。 但是,發展 語音識別軟件 這不是一項簡單的任務——正是因為轉錄人類語言的所有復雜性,如節奏、口音、音高和清晰度是很困難的。 而且,當你在這個複雜的組合中加入情感時,它就變成了一個挑戰。
什麼是語音識別?
語音識別是軟件識別和處理的能力 人類語言 成文字。 雖然語音識別和語音識別之間的差異對許多人來說似乎是主觀的,但兩者之間存在一些根本差異。
儘管語音和語音識別都是語音助手技術的一部分,但它們執行兩種不同的功能。 語音識別自動將人類語音和命令轉錄成文本,而語音識別只處理識別說話者的聲音。
語音識別的類型
在我們進入之前 語音識別類型,我們來簡單看一下語音識別數據。
語音識別數據是人類語音錄音和文本轉錄的集合,有助於訓練機器學習系統 語音識別.
錄音和轉錄被輸入到機器學習系統中,這樣算法就可以被訓練來識別語音的細微差別並理解其含義。
雖然有很多地方可以獲取免費的預打包數據集,但最好獲取 自定義數據集 為您的項目。 您可以通過自定義數據集來選擇集合大小、音頻和揚聲器要求以及語言。
語音數據頻譜
語音數據 頻譜識別從自然到不自然的語音質量和音調。
腳本語音識別數據
顧名思義,腳本語音是一種受控形式的數據。 演講者從準備好的文本中錄製特定的短語。 這些通常用於傳遞命令,強調如何 單詞或短語 是說而不是在說什麼。
在開發語音助手時可以使用腳本語音識別,該語音助手應該接收使用不同說話者口音發出的命令。
基於場景的語音識別
在基於情景的演講中,演講者被要求想像一個特定的情景並發出一個 語音指揮 根據場景。 通過這種方式,結果是一組未編寫腳本但受控的語音命令。
希望開發能夠理解日常語音及其各種細微差別的設備的開發人員需要基於場景的語音數據。 例如,使用各種問題詢問前往最近的必勝客的路線。
自然語音識別
就在語音頻譜的末端是自發的、自然的、不受任何控制的語音。 演講者使用他自然的談話語氣、語言、音高和男高音自由地說話。
如果您想在多說話人語音識別方面訓練基於 ML 的應用程序,那麼一個無腳本或 會話式演講 數據集很有用。
語音項目的數據收集組件
 語音數據收集涉及的一系列步驟可確保收集到的數據具有質量,並有助於訓練高質量的基於 AI 的模型。
語音數據收集涉及的一系列步驟可確保收集到的數據具有質量,並有助於訓練高質量的基於 AI 的模型。
了解所需的用戶響應
首先了解模型所需的用戶響應。 要開發語音識別模型,您應該收集與您需要的內容密切相關的數據。 從真實世界的交互中收集數據以了解用戶交互和響應。 如果您正在構建基於 AI 的聊天助手,請查看聊天日誌、通話記錄、聊天對話框響應以創建數據集。
審查特定領域的語言
您需要語音識別數據集的通用內容和特定領域的內容。 收集通用語音數據後,您應該篩選數據並將通用與特定分開。
例如,客戶可以打電話要求預約在眼保健中心檢查青光眼。 預約是一個高度通用的術語,但青光眼是特定領域的。
此外,在訓練語音識別 ML 模型時,請確保訓練它以識別短語而不是單獨 公認的詞.
錄製人類語音
在從前兩個步驟收集數據之後,下一步將涉及讓人類記錄收集到的語句。
保持腳本的理想長度至關重要。 要求人們閱讀超過 15 分鐘的文字可能會適得其反。 在每條記錄的陳述之間保持至少 2-3 秒的間隔。
允許錄製是動態的
建立一個包含不同人、口音、風格在不同情況、設備和環境下記錄的語音庫。 如果大多數未來用戶將使用固定電話,那麼您的語音收集數據庫應該具有符合該要求的重要表示。

誘導語音記錄的可變性
設置好目標環境後,請您的數據收集主體在類似環境下閱讀準備好的腳本。 要求受試者不要擔心錯誤並儘可能自然地進行演繹。 這個想法是讓一大群人在同一環境中錄製腳本。
轉錄演講稿
使用多個主題(有錯誤)錄製腳本後,您應該繼續轉錄。 保持錯誤完好無損,因為這將幫助您在收集的數據中獲得活力和多樣性。
您可以使用語音到文本引擎來進行轉錄,而不是讓人類逐字轉錄整個文本。 但是,我們也建議您僱用人工抄錄員來糾正錯誤。
開發測試集
開發測試集至關重要,因為它是 語言模型.
製作一對語音和相應的文本,並將它們分成片段。
收集到的元素後,抽取20%的樣本,形成測試集。 它不是訓練集,但是這個提取的數據會讓你知道訓練的模型是否轉錄了它沒有訓練過的音頻。
建立語言訓練模型和度量
現在,如果需要,使用特定領域的語句和其他變體來構建語音識別語言模型。 一旦你訓練了模型,你應該開始測量它。
採用訓練模型(選擇 80% 的音頻片段)並針對測試集(提取的 20% 數據集)對其進行測試,以檢查預測和可靠性。 檢查錯誤、模式,並關注可以修復的環境因素。
可能的用例或應用程序
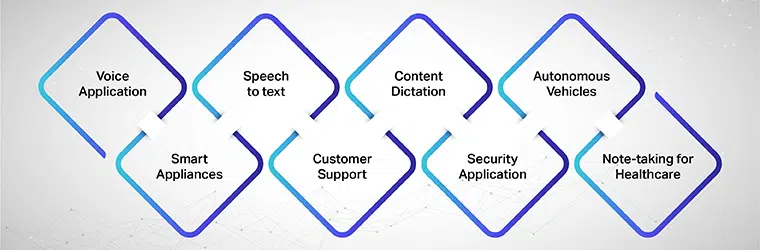
語音應用、智能設備、語音轉文本、客戶支持、內容聽寫、安全應用、自動駕駛汽車、醫療保健筆記。
語音識別打開了一個充滿可能性的世界,並且多年來語音應用程序的用戶採用率有所增加。
一些常見的應用 語音識別技術 包括:
語音搜索應用程序
根據Google的說法, 約20% 在 Google 應用上進行的搜索是語音搜索。 八十億人 預計到 2023 年將使用語音助手,比 6.4 年預計的 2022 億人大幅增加。
多年來,語音搜索的採用率顯著增加,預計這一趨勢將持續下去。 消費者依靠語音搜索來搜索查詢、購買產品、定位企業、查找本地企業等等。
家用設備/智能家電
語音識別技術被用於向家庭智能設備(如電視、燈和其他電器)提供語音命令。 66%的消費者 在英國、美國和德國表示,他們在使用智能設備和揚聲器時會使用語音助手。
語音轉文字
在鍵入電子郵件、文檔、報告和其他內容時,語音轉文本應用程序被用於幫助免費計算。 語音轉文字 消除了輸入文檔、寫書和郵件、字幕視頻和翻譯文本的時間。
客戶服務
語音識別應用程序主要用於客戶服務和支持。 語音識別系統有助於以有限的代表以可承受的成本提供 24/7 的客戶服務解決方案。
內容聽寫
內容聽寫是另一回事 語音識別用例 這可以幫助學生和學者在很短的時間內編寫大量內容。 對於因失明或視力問題而處於劣勢的學生非常有幫助。
安全應用
通過識別獨特的語音特徵,語音識別被廣泛用於安全和身份驗證目的。 語音生物識別技術不是讓個人使用被盜或濫用的個人信息來識別自己,而是提高了安全性。
此外,出於安全目的的語音識別提高了客戶滿意度,因為它消除了擴展的登錄過程和憑據複製。
車輛語音指令
車輛,主要是汽車,現在具有共同的語音識別功能,以提高駕駛安全性。 它通過接受簡單的語音命令(例如選擇電台、撥打電話或降低音量)來幫助駕駛員專注於駕駛。
醫療保健筆記
使用語音識別算法構建的醫療轉錄軟件可以輕鬆捕捉醫生的語音記錄、命令、診斷和症狀。 醫學筆記提高了醫療保健行業的質量和緊迫性。
您是否有一個可以改變您的業務的語音識別項目? 您可能需要的只是一個定制的語音識別數據集。
基於人工智能的語音識別軟件需要在機器學習算法的可靠數據集上進行訓練,以整合人類語音的句法、語法、句子結構、情感和細微差別。 最重要的是,軟件應該不斷學習和響應——隨著每次交互而增長。
在 Shaip,我們為各種機器學習項目提供完全定制的語音識別數據集。 使用 Shaip,您可以訪問 最高質量的定制訓練數據 可用於構建和銷售可靠的語音識別系統。 與我們的專家聯繫,全面了解我們的產品。
[另請閱讀: 對話式 AI 完整指南]