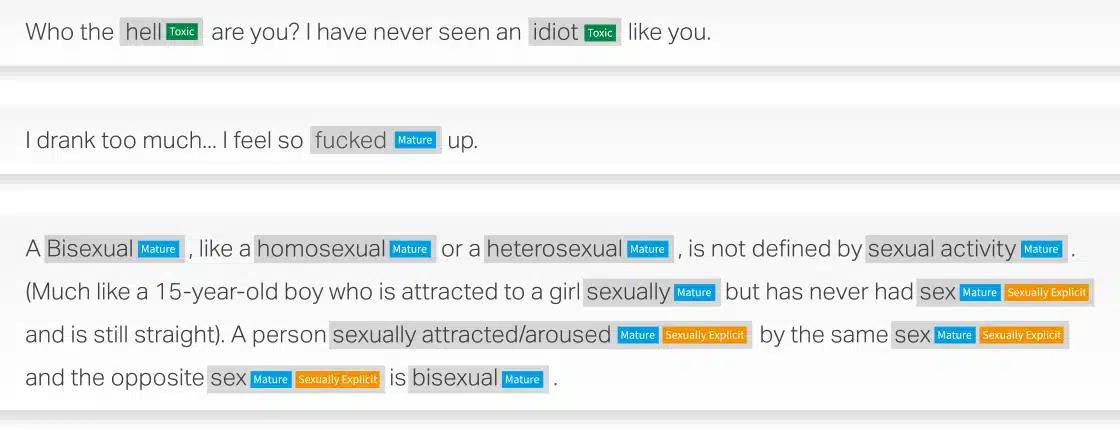
案例研究:內容審核30K+ 文檔 web 報廢和註釋內容審核 下載案例研究 對 AI 驅動的內容審核的需求不斷增加努力保護我們連接和交流的在線空間。 隨著社交媒體使用量的持續增長,網絡欺凌問題已經浮出水面平台努力的重大障礙確保安全的在線空間。 一個驚人的38% 的人遇到過這種情況每天的有害行為,強調對創造性的迫切需求內容審核方法。今天的組織依賴於使用人工智能解決持久性問題主動解決網絡欺凌問題。 網絡安全:Facebook 第四季度社區標準執行報告披露——對 4 萬條欺凌和騷擾內容採取行動,主動檢測率為 6.3% 教育程度: A 2021 研究發現 企業排放佔全球 36.5%美國 % 的學生年齡介於 12和17 年在他們上學期間曾經歷過網絡欺凌。 根據 2020 年的一份報告,4.07 年全球內容審核解決方案市場價值 2019 億美元,預計到 11.94 年將達到 2027 億美元,複合年增長率為 14.7%。 真實世界的解決方案調節全球對話的數據客戶正在開發一個強大的自動化內容審核機器學習其云產品的模型,為此他們正在尋找特定領域的供應商可以幫助他們提供準確的訓練數據。利用我們在自然語言處理 (NLP) 方面的廣泛知識,我們協助客戶收集、分類和註釋了 30,000 多份英語和西班牙語文檔,以構建自動內容審核機器學習模型,分為有毒、成人或色情內容類別。 問題 從優先域中抓取 30,000 份西班牙語和英語文檔將收集到的內容分為短、中、長段將編譯後的數據標記為有毒、成人或露骨色情內容確保高質量的註釋,準確率至少為 90%。 解決方案 Web 從 BFSI、醫療保健、製造、零售中分別收集了 30,000 份西班牙語和英語文檔。 內容進一步分為短、中、長文檔 成功將分類內容標記為有毒、成人或露骨色情內容為了達到 90% 的質量,Shaip 實施了兩層質量控制流程:» 級別 1:質量保證檢查:100% 的文件進行驗證。» 級別 2:關鍵質量分析檢查:Shaips 的 CQA 團隊評估 15%-20% 的回顧性樣本。 結果 培訓數據有助於構建自動化內容審核 ML 模型,該模型可以產生多種有益於維護更安全的在線環境的結果。 一些主要成果包括:處理大量數據的效率確保統一執行適度政策的一致性適應不斷增長的用戶群和內容量的可擴展性實時審核可以識別和刪除生成的潛在有害內容通過減少對人類主持人的依賴來提高成本效益 內容審核示例 加速您的對話式 AI 應用程序開發 100% 預約產品介紹 創建臨床 NLP 是一項關鍵任務,需要大量的領域專業知識來解決。 我可以清楚地看到你在這方面領先谷歌幾年。 我想和你一起工作並擴大你的規模。 Google,Inc. 董事 在開發醫療保健語音 API 期間,我的工程團隊與 Shaip 的團隊合作了 2 年以上。 他們在特定於醫療保健的 NLP 方面所做的工作以及他們能夠使用複雜數據集實現的目標給我們留下了深刻的印象。 Google,Inc. 工程主管 告訴我們我們如何為您的下一個 AI 計劃提供幫助。 聯絡我們