

文字分類
關於文本註釋的最基本方法,側重於根據內容類型、意圖、情感和主題對文本進行分類。 分類後,數據集作為預定義段的一部分輸入系統,機器可以訪問這些段以生成響應

語言註釋
最初稱為語料庫註釋,這種形式的文本數據集標註側重於音頻和文本的語言細節; 此外,它還需要語音註釋、語義註釋、詞性標註等。這種方法在訓練機器翻譯模型時很重要

實體註解
這種標記方法在聊天機器人培訓方面至關重要。 這裡的重點在於在將數據輸入系統之前提取、定位和標記實體。 與任何由聊天機器人驅動的界面一樣,名稱實體、關鍵短語和 POS(如形容詞、副詞等)成為核心。

實體鏈接
雖然註釋者從更大的數據存儲庫中提取實體,但它們需要相互鏈接以形成具有意義的數據集。 這是為數不多的文本註釋工具之一,包括通過消歧和最終端到端鏈接建立完整的知識數據庫。 例如,URL 路由,直接從聊天界面
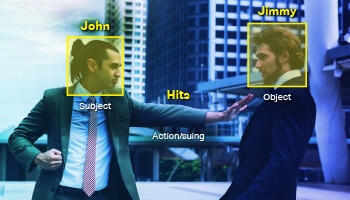
SAO(主題動作對象)
當文本包含多個實體時,由操作鏈接。 例如,“John hits Jimmy”對實體註釋和文本分類開放,其中添加了有關基於法律的討論的標籤。 然而,為了讓模型理解句子,它需要輸入 SAO 數據,John 是主語,Jimmy 是賓語,而 suing 是動作。
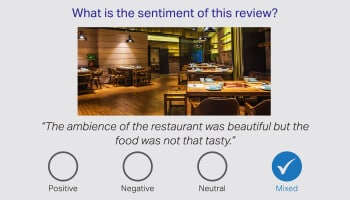
情感註解
情感註釋負責情感標籤,並允許智能設置檢測隱藏的內涵、觀點和特定情感。 註釋者被分配了審查文本並將其標記為消極、中立和積極情緒的責任。 而意圖註釋側重於查詢的願望。

員工
專門和訓練有素的團隊:
- 30,000 多名數據創建、標籤和 QA 協作者
- 有資質的項目管理團隊
- 經驗豐富的產品開發團隊
- 人才庫採購和入職團隊

過程
通過以下方式確保最高的流程效率:
- 穩健的 6 Sigma Stage-Gate 工藝
- 一個由 6 Sigma 黑帶組成的專門團隊——關鍵流程負責人和質量合規
- 持續改進和反饋循環

平台
獲得專利的平台具有以下優勢:
- 基於網絡的端到端平台
- 無可挑剔的品質
- 更快的 TAT
- 無縫交付
員工
專門和訓練有素的團隊:
- 30,000 多名數據創建、標籤和 QA 協作者
- 有資質的項目管理團隊
- 經驗豐富的產品開發團隊
- 人才庫採購和入職團隊
過程
通過以下方式確保最高的流程效率:
- 穩健的 6 Sigma Stage-Gate 工藝
- 一個由 6 Sigma 黑帶組成的專門團隊——關鍵流程負責人和質量合規
- 持續改進和反饋循環
平台
獲得專利的平台具有以下優勢:
- 基於網絡的端到端平台
- 無可挑剔的品質
- 更快的 TAT
- 無縫交付
音頻註釋
服務
通過語音識別、說話人分類、情感識別等相關工具標記音頻源、語音和特定於語音的數據集是 Shaip 的專長。

圖像註釋
服務
我們以標記、分割圖像數據集來訓練有辨識力的計算機視覺模型而自豪。 一些相關技術包括邊界識別和圖像分類。

視頻註釋
服務
Shaip 提供用於訓練計算機視覺模型的高端視頻標記服務。 這裡的目的是使數據集可用於模式識別、對象檢測等工具。


