


問答對
文字摘要
圖片說明
音頻生成
法學碩士數據評估
法學碩士數據比較
綜合對話創造
圖像摘要、評級和驗證
問答對
創建問答對
關鍵字查詢創建
順序問答
RAG 問答驗證
創建問答對

關鍵字查詢創建

順序問答

RAG 問答驗證

文字摘要
段落總結
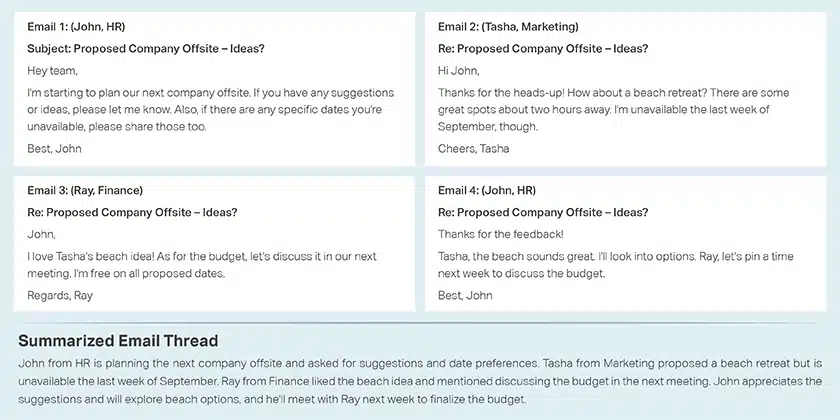
電子郵件摘要
對話總結
段落總結

電子郵件摘要
對話總結
圖片說明

音頻生成

法學碩士數據評估

法學碩士數據比較

綜合對話創造
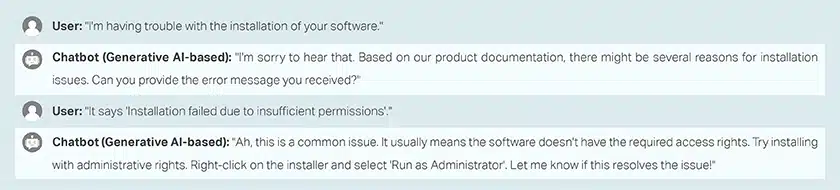
聊天機器人培訓問答
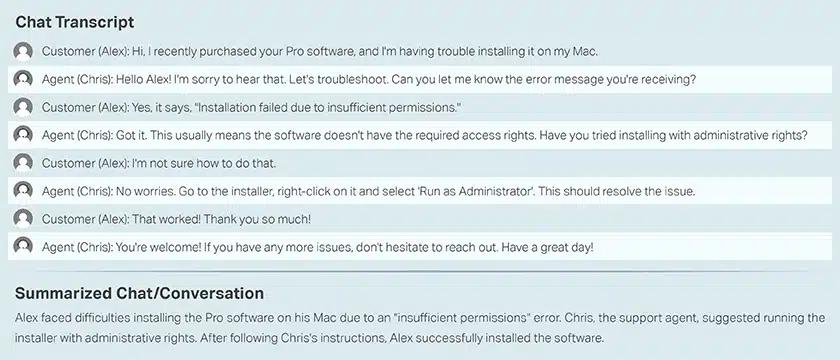
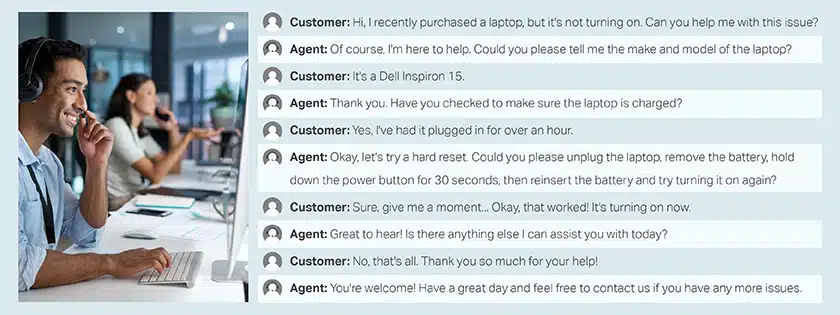
呼叫中心對話客戶和代理
聊天機器人培訓問答
呼叫中心對話客戶和代理
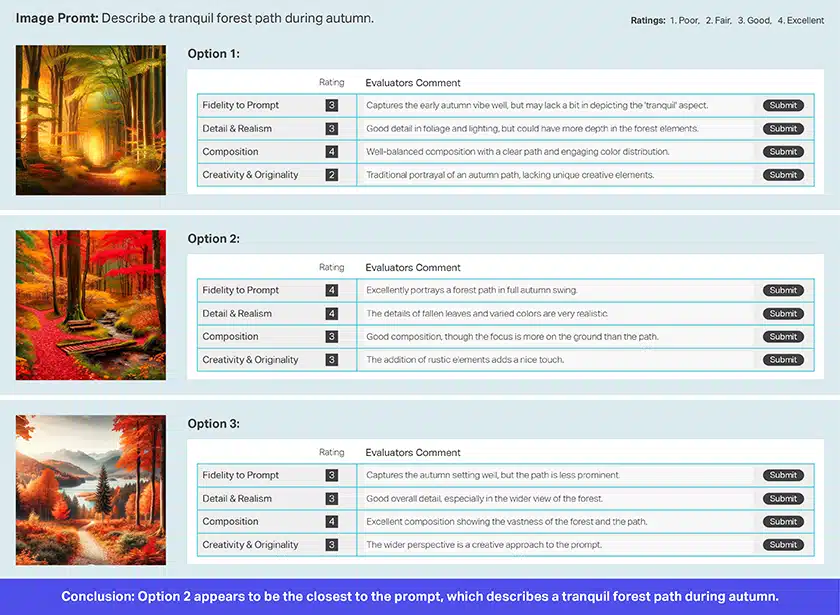
圖像摘要、評級和驗證
圖像評級
影像驗證
影像摘要
圖像評級
影像驗證
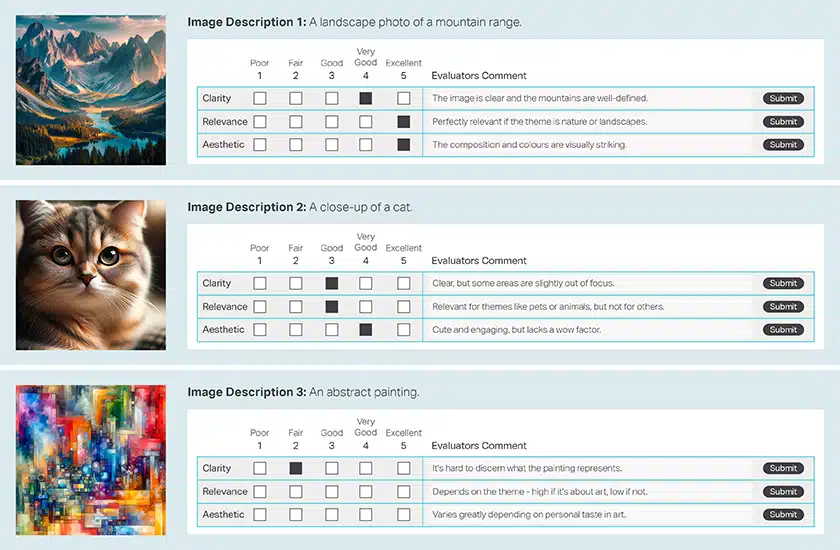
影像摘要




創建臨床 NLP 是一項關鍵任務,需要大量的領域專業知識來解決。 我可以清楚地看到你在這方面領先谷歌幾年。 我想和你一起工作並擴大你的規模。
Google,Inc. 董事
在開發醫療保健語音 API 期間,我的工程團隊與 Shaip 的團隊合作了 2 年以上。 他們在特定於醫療保健的 NLP 方面所做的工作以及他們能夠使用複雜數據集實現的目標給我們留下了深刻的印象。
Google,Inc. 工程主管