
克服人工智能發展障礙的關鍵:更可靠的數據
今天,普通人現在口袋裡的計算能力是美國宇航局 1969 年登月時的數百萬倍。 同樣無處不在的設備,方便地展示了豐富的計算能力,也滿足了人工智能黃金時代的另一個先決條件:大量數據。 根據信息過載研究小組的見解,全球 90% 的數據是在過去兩年中創建的。 現在,計算能力的指數級增長最終與數據生成的同樣快速增長相融合,人工智能數據創新正在爆炸式增長,以至於一些專家認為將啟動第四次工業革命。
來自美國國家風險投資協會的數據顯示,人工智能領域在 6.9 年第一季度的投資達到創紀錄的 2020 億美元。不難看出人工智能工具的潛力,因為它已經在我們身邊被挖掘。 AI 產品的一些更明顯的用例是我們最喜歡的應用程序(如 Spotify 和 Netflix)背後的推薦引擎。 雖然發現一個新的藝術家來聽或一個新的電視節目來狂歡很有趣,但這些實現的風險相當低。 其他算法對考試成績進行評分——部分確定學生被大學錄取的位置——還有一些算法篩選候選人簡歷,決定哪些申請人獲得特定工作。 一些人工智能工具甚至可以產生生死攸關的影響,例如篩查乳腺癌的人工智能模型(其表現優於醫生)。
儘管 AI 開發的真實案例和競爭創建下一代轉型工具的初創公司數量穩步增長,但有效開發和實施的挑戰仍然存在。 特別是,AI 輸出僅在輸入允許的範圍內準確,這意味著質量至關重要。

駕馭複雜的合規性需求
似乎找到高質量的數據還不夠困難,一些從 AI 數據創新中獲益最多的行業也受到最嚴格的監管。 醫療保健可能是最好的例子,雖然 HIT Infrastructure 的一項調查發現,91% 的業內人士認為該技術可以改善獲得護理的機會,但由於 75% 的人將其視為對患者安全和隱私的威脅,這種樂觀情緒有所減弱- 患者並不是唯一面臨風險的人。
通過《健康保險流通與責任法案》頒布的全面法規現在與各種本地數據合規障礙交叉,例如歐洲的通用數據保護條例、美國的加利福尼亞消費者隱私法和新加坡的個人數據保護法。 更多的地方法規將加入這些地方法規,並且隨著遠程醫療成為更重要的醫療保健數據來源,法規可能會更嚴格地控制傳輸中的患者數據。 因此,Shaip 的安全且合規的雲平台將被證明是一種更有價值的收集和訪問醫療數據以訓練 AI 產品的手段。
個人可識別信息可能對您的 AI 開發構成重大威脅,但如果無法提供只有多樣化訓練數據才能提供的準確結果,即使是完全合規的實施也存在風險。 《美國醫學會雜誌》2020 年的一項研究表明,醫學領域的機器學習算法最常使用來自加利福尼亞、紐約和馬薩諸塞州患者的數據進行訓練。 鑑於這些患者只占美國人口的不到五分之一,更不用說世界其他地方了,很難想像這些模型除了產生有偏見的結果之外,還能產生什麼結果。

 Shaip 認識到保護合規的、地域多樣的信息的難度,提供了來自各種地區的許可醫療保健數據,專門策劃以構建準確的算法為目的。 這些數據以文本形式出現,例如醫療記錄或理賠信息、CT 掃描等醫學診斷成像、醫生口述或醫患對話等音頻,甚至 MRI 結果中的視頻。 它還完全去標識化和匿名化,保護您的組織免受道德和財務影響,這些影響可能會因違反越來越多的管理國內和國際來源數據的法規而產生。
Shaip 認識到保護合規的、地域多樣的信息的難度,提供了來自各種地區的許可醫療保健數據,專門策劃以構建準確的算法為目的。 這些數據以文本形式出現,例如醫療記錄或理賠信息、CT 掃描等醫學診斷成像、醫生口述或醫患對話等音頻,甚至 MRI 結果中的視頻。 它還完全去標識化和匿名化,保護您的組織免受道德和財務影響,這些影響可能會因違反越來越多的管理國內和國際來源數據的法規而產生。
克服人工智能發展障礙
無論在哪個行業,人工智能的開發工作都存在重大障礙,從一個可行的想法到成功的產品的過程充滿了困難。 在獲取正確數據的挑戰和將其匿名化以符合所有相關法規的需求之間,感覺實際上構建和訓練算法是容易的部分。
為了讓您的組織在設計突破性的新 AI 開發的工作中獲得一切必要的優勢,您需要考慮與像 Shaip 這樣的公司合作。 Chetan Parikh 和 Vatsal Ghiya 創立了 Shaip,旨在幫助公司設計可以改變美國醫療保健的各種解決方案。經過 16 年的經營,我們公司已經發展到擁有 600 多名團隊成員,我們已經與數百名客戶將引人注目的想法轉化為 AI 解決方案。
通過我們的人員、流程和平台為您的組織工作,您可以立即獲得以下四個好處,並推動您的項目取得成功:
1. 解放數據科學家的能力
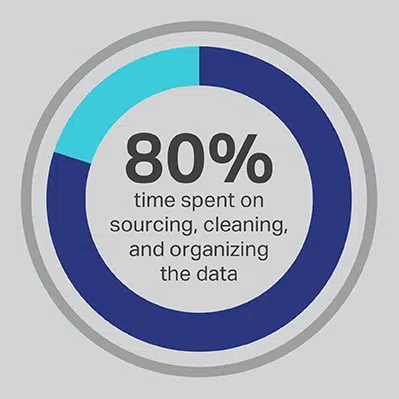
AI 開發過程需要花費大量時間,這是無可避免的,但您始終可以優化團隊花費最多時間執行的功能。 您聘請數據科學家是因為他們是高級算法和機器學習模型開發方面的專家,但研究一致表明,這些員工實際上將 80% 的時間用於採購、清理和組織將為項目提供動力的數據。 超過四分之三 (76%) 的數據科學家報告說,這些平凡的數據收集過程也恰好是他們工作中最不喜歡的部分,但對高質量數據的需求只留下了 20% 的時間用於實際開發,這是對於許多數據科學家來說,這是最有趣和最能激發智力的工作。 通過通過第三方供應商(如 Shaip)採購數據,公司可以讓其昂貴且才華橫溢的數據工程師將他們的工作外包為數據管理員,而將時間花在人工智能解決方案的部分上,在那裡他們可以產生最大的價值。
2. 取得更好結果的能力
 許多人工智能開發領導者決定使用開源或眾包數據來減少開支,但從長遠來看,這一決定幾乎總是導致成本增加。 這些類型的數據很容易獲得,但它們無法與精心策劃的數據集的質量相匹配。 眾包數據尤其充斥著錯誤、遺漏和不准確之處,雖然這些問題有時可以在開發過程中在工程師的監督下解決,但如果您開始使用更高級別的數據,則不需要額外的迭代。 - 質量數據從一開始。
許多人工智能開發領導者決定使用開源或眾包數據來減少開支,但從長遠來看,這一決定幾乎總是導致成本增加。 這些類型的數據很容易獲得,但它們無法與精心策劃的數據集的質量相匹配。 眾包數據尤其充斥著錯誤、遺漏和不准確之處,雖然這些問題有時可以在開發過程中在工程師的監督下解決,但如果您開始使用更高級別的數據,則不需要額外的迭代。 - 質量數據從一開始。
依賴開源數據是另一種常見的捷徑,但也有一些陷阱。 缺乏差異化是最大的問題之一,因為使用開源數據訓練的算法比建立在許可數據集上的算法更容易複製。 通過這條路線,您會邀請該領域其他進入者的競爭,他們可以隨時降低您的價格並搶占市場份額。 當您依賴 Shaip 時,您將訪問由熟練管理的勞動力收集的最高質量的數據,我們可以授予您自定義數據集的獨家許可,以防止競爭對手輕鬆地重新創建您來之不易的知識產權。
3. 接觸經驗豐富的專業人士
 即使您的內部名冊包括熟練的工程師和才華橫溢的數據科學家,您的 AI 工具也可以從只有通過經驗而來的智慧中受益。 我們的主題專家在他們的領域率先實施了許多人工智能,並在此過程中吸取了寶貴的經驗教訓,他們的唯一目標是幫助您實現自己的目標。
即使您的內部名冊包括熟練的工程師和才華橫溢的數據科學家,您的 AI 工具也可以從只有通過經驗而來的智慧中受益。 我們的主題專家在他們的領域率先實施了許多人工智能,並在此過程中吸取了寶貴的經驗教訓,他們的唯一目標是幫助您實現自己的目標。
通過領域專家為您識別、組織、分類和標記數據,您知道用於訓練算法的信息可以產生最佳結果。 我們還定期進行質量保證,以確保數據符合最高標準,並且不僅在實驗室中,而且在現實世界中都能按預期執行。
4. 加速開發時間表
AI 開發不會在一夜之間發生,但是當您與 Shaip 合作時,它會發生得更快。 內部數據收集和註釋造成了嚴重的操作瓶頸,阻礙了其餘的開發過程。 與 Shaip 合作可讓您即時訪問我們龐大的即用型數據庫,我們的專家將能夠利用我們深厚的行業知識和全球網絡獲取您需要的任何類型的額外輸入。 沒有採購和註釋的負擔,您的團隊可以立即開始實際開發工作,我們的訓練模型可以幫助識別早期不准確之處,以減少實現準確度目標所需的迭代。
如果您不准備外包數據管理的所有方面,Shaip 還提供了一個基於雲的平台,可幫助團隊更有效地生成、更改和註釋不同類型的數據,包括對圖像、視頻、文本和音頻的支持. ShaipCloud 包括各種直觀的驗證和工作流程工具,例如用於跟踪和監控工作負載的專利解決方案、用於轉錄複雜和困難的錄音的轉錄工具以及用於確保不妥協質量的質量控制組件。 最重要的是,它是可擴展的,因此可以隨著項目的各種需求的增加而增長。
AI 創新的時代才剛剛開始,未來幾年我們將看到令人難以置信的進步和創新,這些進步和創新有可能重塑整個行業甚至改變整個社會。 在 Shaip,我們希望利用我們的專業知識成為一股變革力量,幫助世界上最具革命性的公司利用人工智能解決方案的力量來實現雄心勃勃的目標。
我們在醫療保健應用程序和對話式 AI 方面擁有豐富的經驗,但我們也擁有為幾乎任何類型的應用程序訓練模型的必要技能。 有關 Shaip 如何幫助您將項目從創意變為實施的更多信息,請查看我們網站上提供的許多資源或立即與我們聯繫。
