






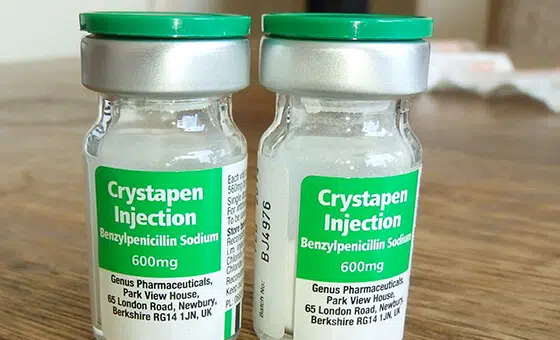



- 用例: 物體識別模型
- 格式: 影片
- 體積: 5,000+
- 註解: 沒有

- 用例: 博士。 識別模型
- 格式: 圖片
- 體積: 15,900+
- 註解: 沒有
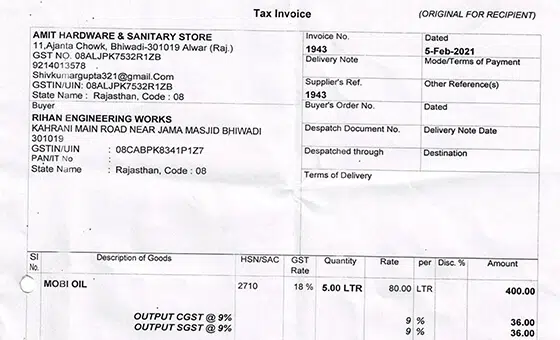
- 用例: 發票識別。 模型
- 格式: 圖片
- 體積: 45,000+
- 註解: 沒有

- 用例: 號牌識別
- 格式: 圖片
- 體積: 3,500+
- 註解: 沒有

- 用例: OCR 模型
- 格式: 圖片
- 體積: 90,000+
- 註解: 是

- 用例: 多語言 OCR 模型
- 格式: 圖片
- 體積: 23,500+
- 註解: 是
- 用例: 物體檢測模型
- 格式: 圖片
- 體積: 11,500+
- 註解: 沒有

- 用例: 收據 AI 模型
- 格式: 圖片
- 體積: 75,000+
- 註解: 沒有

員工
專門和訓練有素的團隊:
- 30,000 多名數據收集、標記和 QA 合作者
- 有資質的項目管理團隊
- 經驗豐富的產品開發團隊
- 人才庫採購和入職團隊

過程
通過以下方式確保最高的流程效率:
- 穩健的 6 Sigma Stage-Gate 工藝
- 一個由 6 Sigma 黑帶組成的專門團隊——關鍵流程負責人和質量合規
- 持續改進和反饋循環

平台
獲得專利的平台具有以下優勢:
- 基於網絡的端到端平台
- 無可挑剔的品質
- 更快的 TAT
- 無縫交付



創建臨床 NLP 是一項關鍵任務,需要大量的領域專業知識來解決。 我可以清楚地看到你在這方面領先谷歌幾年。 我想和你一起工作並擴大你的規模。
Google,Inc. 董事
在開發醫療保健語音 API 期間,我的工程團隊與 Shaip 的團隊合作了 2 年以上。 他們在特定於醫療保健的 NLP 方面所做的工作以及他們能夠使用複雜數據集實現的目標給我們留下了深刻的印象。
Google,Inc. 工程主管