簡介
 人工智能就是使用機器來提升人們的生活和生活方式,讓他們的平凡生活變得有趣和簡單。 人工智能永遠不應該是一種主導力量,而是一種互補的力量,它與人類協同工作以解決難以置信的問題並為集體進化鋪平道路。
人工智能就是使用機器來提升人們的生活和生活方式,讓他們的平凡生活變得有趣和簡單。 人工智能永遠不應該是一種主導力量,而是一種互補的力量,它與人類協同工作以解決難以置信的問題並為集體進化鋪平道路。
截至目前,我們正走在正確的道路上,在人工智能的幫助下,各個行業都取得了重大突破。 以醫療保健為例,帶有機器學習模型的人工智能係統正在幫助專家更好地了解癌症並提出治療方法。 神經系統疾病和創傷後應激障礙等問題正在人工智能的幫助下得到治療。 由於人工智能驅動的臨床試驗和模擬,疫苗正在快速開發中。
不僅僅是醫療保健,人工智能涉及的每個行業或細分領域都在發生革命性的變化。 自動駕駛汽車、智能便利店、FitBit 等可穿戴設備,甚至我們的智能手機攝像頭都能夠通過 AI 捕捉到更好的面部圖像。
由於人工智能領域的創新,公司正在通過各種用例和解決方案闖入這個領域。 因此,到 267 年底,全球人工智能市場的市值預計將達到約 2027 億美元。此外,大約 37% 的企業已經在其流程和產品中實施人工智能解決方案。
更有趣的是,我們今天使用的產品和服務中有近 77% 是由人工智能提供支持的。 隨著技術概念在垂直領域顯著上升,企業如何利用人工智能做到不可能?

 像手錶這樣簡單的設備如何準確預測人類的心髒病發作? 一直需要司機的汽車和汽車怎麼可能突然在道路上減少司機?
像手錶這樣簡單的設備如何準確預測人類的心髒病發作? 一直需要司機的汽車和汽車怎麼可能突然在道路上減少司機?
聊天機器人如何讓我們相信我們正在與另一邊的另一個人交談?
如果你觀察每一個問題的答案,它就會歸結為一個元素——數據。 數據是所有特定於 AI 的操作和流程的中心。 它是幫助機器理解概念、處理輸入並提供準確結果的數據。
現有的所有主要 AI 解決方案都是我們稱為數據收集或數據採集或 AI 訓練數據的關鍵過程的所有產品。
這份詳盡的指南旨在幫助您了解它是什麼以及它為何重要。
什麼是人工智能數據採集?
機器沒有自己的頭腦。 缺乏這個抽象概念使他們缺乏意見、事實和推理、認知等能力。 它們只是佔據空間的不可移動的盒子或設備。 要將它們變成強大的媒介,您需要算法,更重要的是數據。
 開發的算法需要一些東西來處理和處理,這些東西是相關的、上下文的和最新的數據。 為機器收集此類數據以達到其預期目的的過程稱為人工智能數據收集。
開發的算法需要一些東西來處理和處理,這些東西是相關的、上下文的和最新的數據。 為機器收集此類數據以達到其預期目的的過程稱為人工智能數據收集。
我們今天使用的每一個支持 AI 的產品或解決方案及其提供的結果都源於多年的培訓、開發和優化。 從提供導航路線的設備到提前幾天預測設備故障的複雜系統,每個實體都經歷了多年的人工智能培訓,才能準確交付結果。
人工智能數據採集 是人工智能開發過程中的第一步,從一開始就決定了人工智能係統的有效性和效率。 這是從無數來源獲取相關數據集的過程,這將有助於 AI 模型更好地處理細節並產生有意義的結果。




如何為機器學習收集數據?
 這就是事情開始變得有點棘手的地方。 從一開始,您似乎已經想到了解決現實世界問題的方法,您知道 AI 將是解決此問題的理想方式,並且您已經開發了模型。 但是現在,您正處於需要開始 AI 培訓過程的關鍵階段。 你需要豐富的人工智能訓練數據,讓你的模型學習概念並交付結果。 您還需要驗證數據來測試您的結果並優化您的算法。
這就是事情開始變得有點棘手的地方。 從一開始,您似乎已經想到了解決現實世界問題的方法,您知道 AI 將是解決此問題的理想方式,並且您已經開發了模型。 但是現在,您正處於需要開始 AI 培訓過程的關鍵階段。 你需要豐富的人工智能訓練數據,讓你的模型學習概念並交付結果。 您還需要驗證數據來測試您的結果並優化您的算法。
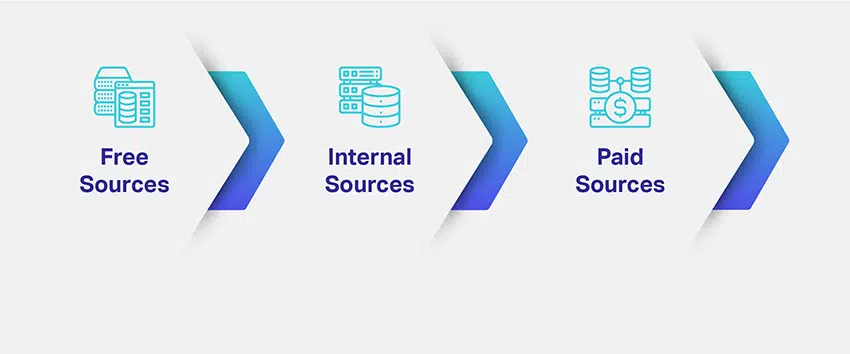
那麼,您如何獲取數據? 您需要哪些數據以及需要多少數據? 獲取相關數據的多個來源是什麼?
公司評估其 ML 模型的利基和目的,並繪製出獲取相關數據集的潛在方法。 定義所需的數據類型可以解決您對數據來源的主要擔憂。 為了讓您有更好的想法,數據收集有不同的渠道、途徑、來源或媒介:
不良數據如何影響您的 AI 抱負?
我們列出了三種最常見的數據資源,因為您將了解如何進行數據收集和採購。 然而,在這一點上,了解您的決定總是會決定您的 AI 解決方案的命運變得至關重要。
與高質量的 AI 訓練數據如何幫助您的模型提供準確及時的結果類似,糟糕的訓練數據也會破壞您的 AI 模型、扭曲結果、引入偏差並產生其他不良後果。
但為什麼會發生這種情況? 不應該有任何數據來訓練和優化您的 AI 模型嗎? 老實說,沒有。 讓我們進一步了解這一點。
壞數據——是什麼?
 不良數據是任何不相關、不正確、不完整或有偏見的數據。 由於定義不明確的數據收集策略,大多數數據科學家和 註釋專家 被迫處理不良數據。
不良數據是任何不相關、不正確、不完整或有偏見的數據。 由於定義不明確的數據收集策略,大多數數據科學家和 註釋專家 被迫處理不良數據。
非結構化數據和不良數據之間的區別在於,對非結構化數據的洞察無處不在。 但本質上,它們無論如何都可能有用。 通過花費更多時間,數據科學家仍然能夠從非結構化數據集中提取相關信息。 但是,對於不良數據,情況並非如此。 這些數據集不包含/有限的見解或信息,這些見解或信息對您的 AI 項目或其培訓目的有價值或相關。
因此,當您從免費資源中獲取數據集或建立鬆散的內部數據接觸點時,您很有可能會下載或生成不良數據。 當您的科學家處理不良數據時,您不僅在浪費人力,而且還在推動產品的發布。
如果您仍然不清楚不良數據會對您的抱負造成什麼影響,這裡有一個快速列表:
- 您花費無數時間尋找不良數據,並在資源上浪費時間、精力和金錢。
- 如果不被注意,錯誤數據可能會給您帶來法律問題,並可能降低您的 AI 的效率
型號。 - 當您將接受不良數據訓練的產品上線時,它會影響用戶體驗
- 糟糕的數據可能會使結果和推論產生偏差,這可能會進一步引起強烈反對。
所以,如果你想知道是否有解決方案,實際上是有的。
AI 訓練數據提供者來救援
 基本的解決方案之一是尋找數據供應商(付費來源)。 AI 培訓數據提供商可確保您收到的內容準確且相關,並且您以結構化的形式向您提供數據集。 您不必參與從門戶移動到門戶以搜索數據集的麻煩。
基本的解決方案之一是尋找數據供應商(付費來源)。 AI 培訓數據提供商可確保您收到的內容準確且相關,並且您以結構化的形式向您提供數據集。 您不必參與從門戶移動到門戶以搜索數據集的麻煩。
您所要做的就是接收數據並訓練您的 AI 模型以求完美。 話雖如此,我們確信您的下一個問題是與數據供應商合作所涉及的費用。 我們知道你們中的一些人已經在製定心理預算,而這正是我們接下來要走的方向。
為您的數據收集項目制定有效預算時要考慮的因素
AI 培訓是一種系統方法,這就是為什麼預算成為其中不可或缺的一部分。 在將大量資金投入 AI 開發之前,應考慮投資回報率、結果準確性、培訓方法等因素。 許多項目經理或企業主在這個階段摸索。 他們做出草率的決定,給他們的產品開發過程帶來不可逆轉的變化,最終迫使他們花費更多。
但是,本節將為您提供正確的見解。 當你坐下來處理 AI 培訓的預算時,三件事或因素是不可避免的。

讓我們詳細看看每一個。
您需要的數據量
我們一直在說,你的 AI 模型的效率和準確性取決於它的訓練程度。 這意味著數據集的數量越多,學習就越多。 但這是非常模糊的。 Dimensional Research 發布的一份報告顯示,企業至少需要 100,000 個樣本數據集來訓練他們的 AI 模型。
通過 100,000 個數據集,我們的意思是 100,000 個質量和相關的數據集。 這些數據集應該具有算法和機器學習模型處理信息和執行預期任務所需的所有基本屬性、註釋和見解。
這是一般的經驗法則,讓我們進一步了解您需要的數據量還取決於另一個複雜的因素,即您的業務用例。 您打算對您的產品或解決方案做什麼也決定了您需要多少數據。 例如,構建推薦引擎的企業與構建聊天機器人的公司具有不同的數據量要求。
數據定價策略
當您最終確定實際需要多少數據後,接下來需要製定數據定價策略。 簡單來說,這意味著您將如何為採購或生成的數據集付費。
一般來說,這些是市場上遵循的常規定價策略:
| 數據類型 | 定價策略 |
|---|---|
| 按單個圖像文件定價 | |
| 按秒、分鐘、一小時或單個幀定價 | |
| 按秒、分鐘或小時定價 | |
| 按單詞或句子定價 |
可是等等。 這又是一個經驗法則。 採購數據集的實際成本還取決於以下因素:
- 必須從哪裡獲取數據集的獨特細分市場、人口統計數據或地理位置
- 用例的複雜性
- 你需要多少數據?
- 您的上市時間
- 任何量身定制的要求等等
如果您觀察一下,您就會知道為您的 AI 項目獲取大量圖像的成本可能會更低,但如果您的規格太多,價格可能會飆升。
您的採購策略
這很棘手。 正如您所見,有多種方法可以為您的 AI 模型生成或獲取數據。 常識表明免費資源是最好的,因為您可以免費下載所需數量的數據集而不會出現任何復雜情況。
現在,付費來源似乎也太貴了。 但這就是增加了一層複雜性的地方。 當您從免費資源中獲取數據集時,您需要花費額外的時間和精力來清理數據集、將它們編譯為特定於業務的格式,然後對它們進行單獨註釋。 在此過程中,您會產生運營成本。
使用付費來源,付款是一次性的,您還可以在需要的時候獲得機器就緒的數據集。 這裡的成本效益是非常主觀的。 如果您覺得自己有能力花時間對免費數據集進行註釋,則可以相應地進行預算。 如果您認為您的競爭激烈且上市時間有限,您可以在市場上產生連鎖反應,那麼您應該更喜歡付費資源。
預算就是分解細節並明確定義每個片段。 這三個因素應該可以作為您未來 AI 培訓預算過程的路線圖。
您是否通過內部數據採集節省了開支?
 在製定預算時,我們探索了免費資源如何迫使您從長遠來看花費更多。 那時,您會不自覺地想知道內部數據採集過程的成本效益。
在製定預算時,我們探索了免費資源如何迫使您從長遠來看花費更多。 那時,您會不自覺地想知道內部數據採集過程的成本效益。
我們知道您仍然對付費來源猶豫不決,這就是為什麼本節將消除您對此的懷疑並闡明內部數據生成所涉及的隱藏成本。
內部數據採集是否昂貴?
是的!
現在,這是一個精心設計的回應。 費用是您花費的任何東西。 在討論免費資源時,我們透露您在此過程中花費了金錢、時間和精力。 這也適用於內部數據採集。
 由於您擁有自定義的接觸點或數據漏斗,這並不意味著您將擁有 機器就緒數據集 到底。 您生成的數據仍然主要是原始的和非結構化的。 您可能在一個地方擁有所需的所有數據,但數據包含的內容將無處不在。
由於您擁有自定義的接觸點或數據漏斗,這並不意味著您將擁有 機器就緒數據集 到底。 您生成的數據仍然主要是原始的和非結構化的。 您可能在一個地方擁有所需的所有數據,但數據包含的內容將無處不在。
最終,您最終將花費在支付員工、數據科學家、註釋員、質量保證專業人員等方面。 您還將在訂閱註釋工具和
CMS、CRM 和其他基礎設施的維護費用。
此外,數據集必然存在偏差和準確性問題,您需要手動對它們進行排序。 如果您的 AI 培訓數據團隊存在人員流失問題,您將不得不花錢招募新成員,讓他們適應您的流程,培訓他們使用您的工具等等。
從長遠來看,您最終會花費更多。 還有註釋費用。 在任何給定時間點,使用內部數據產生的總成本為:
產生的成本 = 註釋者數量 * 每個註釋者的成本 + 平台成本
如果您的 AI 培訓日程安排為數月,請想像一下您將持續產生的費用。 那麼,這是解決數據採集問題的理想解決方案還是有其他選擇?
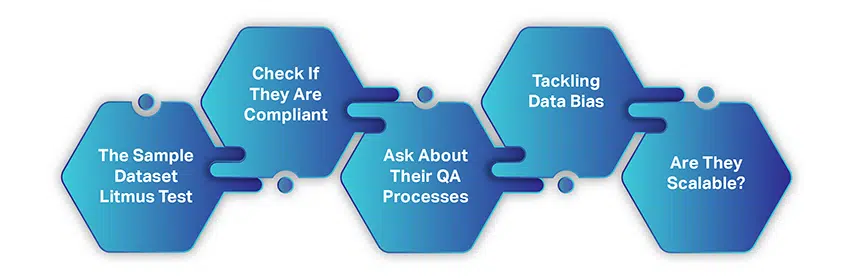
如何選擇合適的人工智能數據採集公司
選擇 AI 數據收集公司並不像從免費資源中收集數據那麼複雜或耗時。 您只需要考慮幾個簡單的因素,然後就可以握手進行合作。
當您開始尋找數據供應商時,我們假設您已經遵循並考慮了我們迄今為止討論的任何內容。 但是,這裡有一個快速回顧:
- 您有一個明確定義的用例
- 您的細分市場和數據要求已經明確
- 您的預算很到位
- 並且您了解所需的數據量
勾選這些項目後,讓我們了解如何尋找理想的訓練數據服務提供商。