
自從計算機開始觀察物體並解釋它們以來,世界就不一樣了。 從可以像 Snapchat 過濾器一樣簡單的娛樂元素,在你的臉上產生有趣的鬍鬚,到復雜的系統,從掃描報告中自動檢測微小腫瘤的存在,計算機視覺在人類進化中發揮著重要作用。
但是,對於未經訓練的 AI 系統,輸入其中的視覺樣本或數據集毫無意義。 你可以輸入熙熙攘攘的華爾街圖片或冰淇淋的圖片,系統不會知道兩者是什麼。 那是因為他們還沒有學會如何對圖像和視覺元素進行分類和分割。
現在,這是一個非常複雜且耗時的過程,需要一絲不苟地關注細節和勞動。 這就是數據註釋專家介入並手動對圖像上的每個字節信息進行屬性或標記的地方,以確保 AI 模型輕鬆學習視覺數據集中的不同元素。 當計算機對帶註釋的數據進行訓練時,它可以輕鬆區分景觀與城市景觀、動物與鳥類、飲料和食物以及其他復雜的分類。
現在我們知道了這一點,數據註釋器如何對圖像元素進行分類和標記? 他們使用了任何特定的技術嗎? 如果是,它們是什麼?
嗯,這正是這篇文章的內容—— 圖像標註 類型、它們的優勢、挑戰和用例。
圖像註釋類型
用於計算機視覺的圖像標註技術可分為五類:
- 物體檢測
- 線路檢測
- 地標檢測
- 分割
- 圖像分類
物體檢測
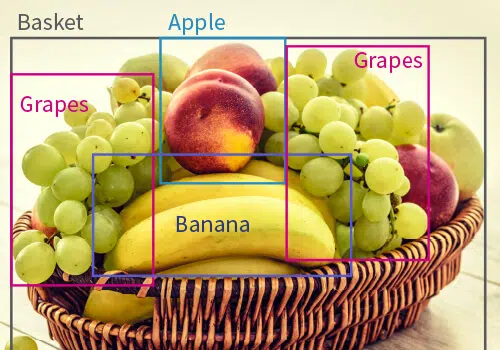 顧名思義,物體檢測的目標是幫助計算機和人工智能模型識別圖像中的不同物體。 為了指定不同的對像是什麼,數據註釋專家採用了三種突出的技術:
顧名思義,物體檢測的目標是幫助計算機和人工智能模型識別圖像中的不同物體。 為了指定不同的對像是什麼,數據註釋專家採用了三種突出的技術:
- 2D 邊界框: 其中繪製和標記了圖像中不同對像上的矩形框。
- 3D 邊界框: 在對像上繪製 3 維框以顯示對象的深度。
- 多邊形: 其中不規則和獨特的物體通過標記物體的邊緣並最終將它們連接在一起以覆蓋物體的形狀來標記。
優點
- 2D 和 3D 邊界框技術非常簡單,可以輕鬆標記對象。
- 3D 邊界框提供了更多細節,例如對象的方向,這在 2D 邊界框技術中是不存在的。
對象檢測的缺點
- 2D 和 3D 邊界框還包括實際上不屬於對象的背景像素。 這以多種方式扭曲了訓練。
- 在 3D 邊界框技術中,註釋者大多假設對象的深度。 這也嚴重影響了訓練。
- 如果對象非常複雜,多邊形技術可能會很耗時。
線路檢測
該技術用於分割、註釋或識別圖像中的線條和邊界。 例如,城市道路上的車道。
優點
這種技術的主要優點是不共享公共邊界的像素也可以被檢測和註釋。 這是註釋短線或被遮擋線的理想選擇。
弊端
- 如果有多條線,則該過程會變得更加耗時。
- 重疊的線條或對象可能會產生誤導性的信息和結果。
地標檢測
數據註釋中的地標並不意味著具有特殊興趣或意義的地方。 它們是圖像中需要註釋的特殊或基本點。 這可能是面部特徵、生物識別技術或更多。 這也稱為姿態估計。
優點
訓練需要地標點精確坐標的神經網絡是理想的。
弊端
這是非常耗時的,因為必須精確註釋每一分鐘的要點。
分割
一個複雜的過程,其中將單個圖像分為多個片段以識別其中的不同方面。 這包括檢測邊界、定位對像等。 為了給您一個更好的主意,這裡列出了一些重要的分割技術:
- 語義分割: 其中圖像中的每個像素都用詳細信息進行了註釋。 對於需要環境背景的模型至關重要。
- 實例分割: 其中圖像中元素的每個實例都針對粒度信息進行了註釋。
- 全景分割: 其中語義和實例分割的細節被包含在圖像中並被註釋。
優點
- 這些技術從物體中提取出最精細的信息。
- 它們為培訓目的增加了更多的背景和價值,最終優化了結果。
弊端
這些技術是勞動密集型和乏味的。
影像分類
 圖像分類涉及識別對像中的元素並將它們分類為特定的對像類。 這種技術與物體檢測技術有很大不同。 在後者中,對象僅被識別。 例如,可以簡單地將貓的圖像註釋為動物。
圖像分類涉及識別對像中的元素並將它們分類為特定的對像類。 這種技術與物體檢測技術有很大不同。 在後者中,對象僅被識別。 例如,可以簡單地將貓的圖像註釋為動物。
但是,在圖像分類中,圖像被歸類為貓。 對於包含多只動物的圖像,每隻動物都會被檢測到並相應地進行分類。
優點
- 為機器提供有關數據集中哪些對象的更多詳細信息。
- 幫助模型準確區分動物(例如)或任何特定於模型的元素。
弊端
需要更多的時間讓數據標註專家仔細識別和分類所有圖像元素。
計算機視覺中圖像標註技術的用例
| 圖像標註技術 | 用例 |
|---|---|
| 2D 和 3D 邊界框 | 非常適合為機器學習系統註釋產品和商品的圖像,以估算成本、庫存等。 |
| 多邊形 | 由於它們能夠註釋不規則物體和形狀,因此它們非常適合在數字成像記錄(如 X 射線、CT 掃描等)中標記人體器官。 它們可用於訓練系統從此類報告中檢測異常和畸形。 |
| 語義分割 | 用於自動駕駛汽車的空間,可以精確標記與車輛運動相關的每個像素。 圖像分類適用於自動駕駛汽車,其中來自傳感器的數據可用於檢測和區分動物、行人、道路物體、車道等。 |
| 地標檢測 | 用於檢測和研究人類情緒以及開發麵部識別系統。 |
| 直線和样條 | 在倉庫和製造單位中很有用,可以為機器人建立邊界以執行自動化任務。 |
結束語
如你所見, 計算機視覺 非常複雜。 有很多錯綜複雜的問題需要處理。 雖然這些看起來和聽起來令人生畏,但其他挑戰包括及時提供高質量數據、無錯誤 數據註釋 流程和工作流程、註釋者的主題專業知識等等。
話雖如此,數據標註公司如 夏普 在向需要它們的公司提供高質量數據集方面做得非常出色。 在接下來的幾個月裡,我們還可以看到這個領域的演變,機器學習系統可以自己準確地以零錯誤的方式註釋數據集。


