
什麼是機器學習中的文本註釋?
機器學習中的文本註釋是指向原始文本數據添加元數據或標籤,以創建用於訓練、評估和改進機器學習模型的結構化數據集。 這是自然語言處理 (NLP) 任務中的關鍵一步,因為它有助於算法根據文本輸入理解、解釋和做出預測。
文本註釋很重要,因為它有助於彌合非結構化文本數據和結構化機器可讀數據之間的差距。 這使得機器學習模型能夠從帶註釋的示例中學習和概括模式。
高質量的註釋對於構建準確且穩健的模型至關重要。 這就是為什麼在文本註釋中仔細關注細節、一致性和領域專業知識至關重要。
文本註釋的類型

訓練 NLP 算法時,必須擁有適合每個項目獨特需求的大型帶註釋文本數據集。 因此,對於想要創建此類數據集的開發人員,這裡簡單概述了五種流行的文本註釋類型。

情感註解
情感註釋識別文本的潛在情感、觀點或態度。 註釋者用積極、消極或中性情緒標籤來標記文本片段。 情感分析是這種註釋類型的關鍵應用,廣泛應用於社交媒體監控、客戶反饋分析和市場研究。
意圖註釋
意圖註釋旨在捕獲給定文本背後的目的或目標。 在這種類型的註釋中,註釋者將標籤分配給代表特定用戶意圖的文本段,例如詢問信息、請求某事或表達偏好。
語義註釋
語義註釋識別單詞、短語和句子之間的含義和關係。 註釋者使用文本分段、文檔分析和文本提取等各種技術來標記和分類文本元素的語義屬性。

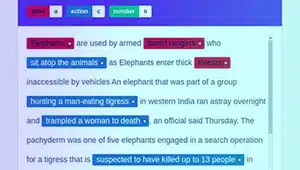
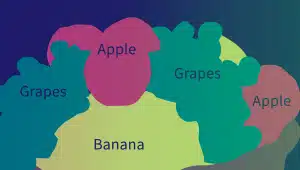
實體註解
實體註釋對於創建聊天機器人訓練數據集和其他 NLP 數據至關重要。 它涉及在文本中查找和標記實體。 實體註釋的類型包括:

語言註釋
語言註釋涉及語言的結構和語法方面。 它包含各種子任務,例如詞性標記、句法分析和形態分析。

医疗保险
文本註釋可幫助保險公司分析客戶反饋、處理索賠和檢測欺詐。 通過使用在帶註釋的數據集上訓練的人工智能模型,保險公司可以:

銀行業
文本註釋有助於改善銀行業的客戶服務、欺詐檢測和文檔分析。 經過註釋數據訓練的人工智能係統可以:

電信
文本註釋使電信公司能夠增強客戶支持、監控社交媒體和管理網絡問題。 在帶註釋的數據集上訓練的機器學習模型可以:
如何註釋文本數據?
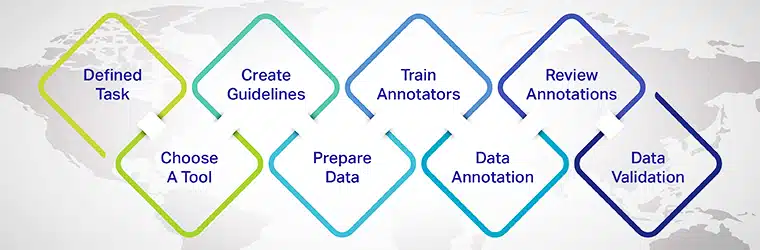
- 定義標註任務: 確定您想要解決的特定 NLP 任務,例如情感分析、命名實體識別或文本分類。
- 選擇合適的標註工具:選擇符合您的項目需求並支持所需註釋類型的文本註釋工具或平台。
- 創建註釋指南:制定清晰一致的指南供註釋者遵循,確保高質量和準確的註釋。
- 選擇並準備數據:收集原始文本數據的多樣化且具有代表性的樣本,供註釋者處理。
- 訓練和評估註釋者:為註釋者提供培訓和持續反饋,確保註釋過程的一致性和質量。
- 註釋數據:註釋者根據定義的準則和註釋類型來標記文本。
- 檢查並完善註釋:定期檢查和完善註釋,解決任何不一致或錯誤,並迭代改進數據集。
- 分割數據集:將標註數據分為訓練集、驗證集和測試集,用於訓練和評估機器學習模型。
夏普能為您做什麼?
Shaip 提供量身定制的服務 文本標註解決方案 為各行業的人工智能和機器學習應用提供支持。 Shaip 專注於高質量和準確的註釋,經驗豐富的團隊和先進的註釋平台可以處理多樣化的文本數據。
無論是情感分析、命名實體識別還是文本分類,Shaip 都能提供自定義數據集來幫助增強 AI 模型的語言理解和性能。
相信 Shaip 能夠簡化您的文本註釋流程,並確保您的 AI 系統充分發揮潛力。

