



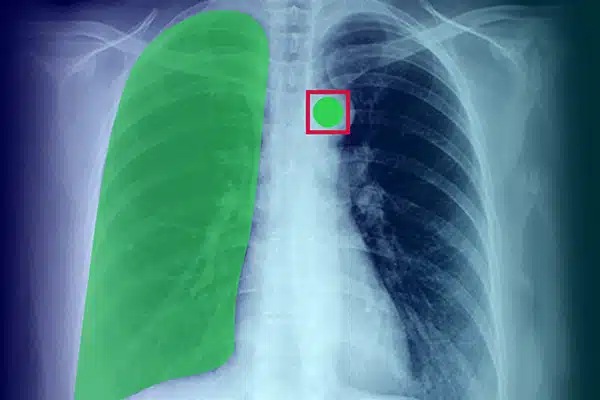
圖像註釋
透過註釋 X 光、CT 掃描和 MRI 的視覺資料來增強醫療 AI。確保人工智慧模型在專家數據標籤的指導下在診斷和治療中表現出色。透過卓越的影像洞察力獲得更好的患者治療效果。
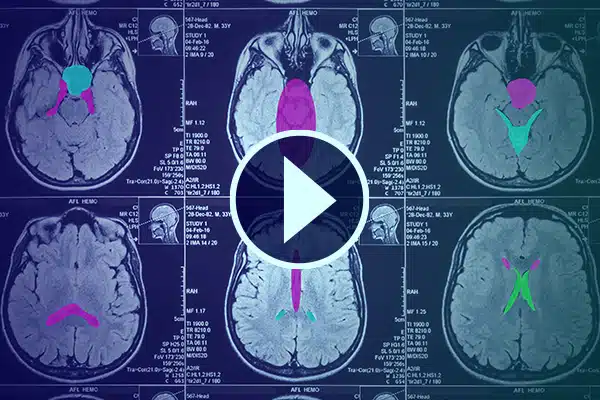
視頻註釋
透過詳細的視訊註釋推進醫療保健領域的人工智慧。透過醫療鏡頭中的分類和分割來強化人工智慧學習。改善您的手術人工智慧和患者監測,以改善醫療服務和診斷。
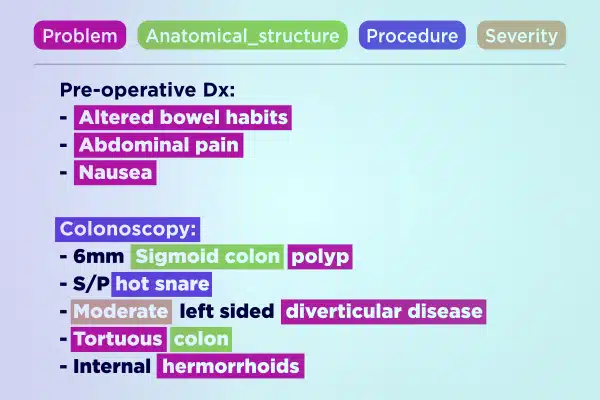
文字註解
利用經過專業註釋的文字資料簡化醫療人工智慧開發。快速解析和豐富大量文本,從手寫筆記到保險報告。確保為醫療保健進步提供準確且可行的見解。

音頻註釋
利用 NLP 專業知識準確註釋和標記醫療音訊資料。打造用於無縫臨床操作的語音輔助系統,並將人工智慧整合到各種聲控醫療保健產品中。透過專家音訊資料管理提高診斷精度。

醫學編碼
透過人工智慧醫療編碼將其轉換為通用代碼,從而簡化醫療文件。透過醫療記錄編碼的尖端人工智慧輔助,確保準確性、提高計費效率並支援無縫醫療保健服務交付。

段落 1: 技術領域專業知識(了解範圍和註釋指南)

段落 2: 為項目培訓適當的資源

段落 3: 註釋文檔的反饋週期和質量保證
放射線學
我們的放射學影像註釋服務增強了人工智慧診斷能力,並增加了一層專業知識。每張 X 光、MRI 和 CT 掃描均經過主題專家的精心標記和審查。訓練和審查的這一額外步驟增強了人工智慧發現異常和疾病的能力。它提高了交付給客戶之前的準確性。

心髒病
我們以心臟病學為中心的圖像註釋增強了人工智慧診斷。我們聘請了心臟病學專家來標記複雜的心臟相關圖像並訓練我們的人工智慧模型。在我們將數據發送給客戶之前,這些專家會審查每張圖像以確保一流的準確性。這個過程使人工智慧能夠更準確地檢測心臟狀況。
牙科
我們的牙科影像註釋服務對牙科影像進行標記,以增強人工智慧診斷工具。透過準確識別蛀牙、排列問題和其他牙齒狀況,我們的中小企業使人工智慧能夠改善患者的治療效果,並支持牙醫進行精確的治療計劃和早期檢測。


















員工
專門和訓練有素的團隊:
- 30,000 多名數據創建、標籤和 QA 協作者
- 有資質的項目管理團隊
- 經驗豐富的產品開發團隊
- 人才庫採購和入職團隊

過程
通過以下方式確保最高的流程效率:
- 穩健的 6 Sigma Stage-Gate 工藝
- 一個由 6 Sigma 黑帶組成的專門團隊——關鍵流程負責人和質量合規
- 持續改進和反饋循環

平台
獲得專利的平台具有以下優勢:
- 基於網絡的端到端平台
- 無可挑剔的品質
- 更快的 TAT
- 無縫交付



