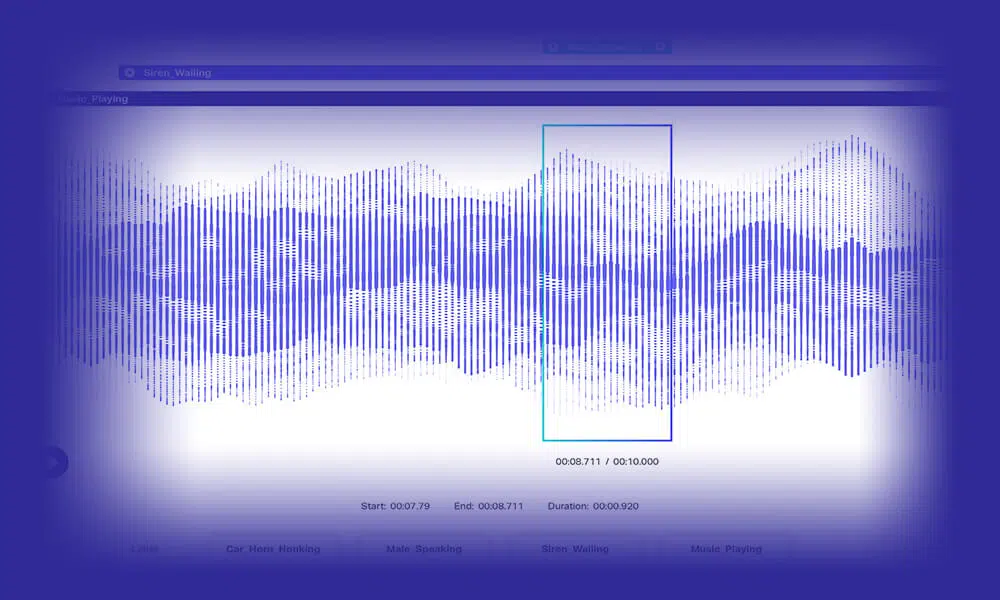

音頻轉錄
通過輸入大量精確轉錄的語音/音頻數據來開發智能 NLP 模型。 在 Shaip,我們讓您從更廣泛的選擇中進行選擇,包括標準音頻、逐字記錄和多語言轉錄。 此外,您可以使用額外的說話者標識符和時間戳數據來訓練模型。
語音標籤
語音或音頻標籤是一種標準註釋技術,涉及分離聲音並使用特定元數據進行標記。 該技術的本質涉及從一段音頻中對聲音進行本體識別,並對其進行準確註釋,使訓練數據集更具包容性

音頻分類
語音註釋公司使用它來訓練 AI 使其完美,涉及根據內容分析錄音。 通過音頻分類,機器可以識別聲音和聲音,同時能夠區分兩者,作為更主動的培訓制度的一部分。

多語言音頻數據服務
只有當註釋者可以相應地標記和分割它們時,收集多語言音頻數據才有用。 這是多語言音頻數據服務派上用場的地方,因為它們涉及基於語言的多樣性對語音進行註釋,由相關的 AI 進行完美的識別和解析

自然語言
發聲
NLU 涉及註釋人類語音以對最小的細節進行分類,如語義、方言、上下文、壓力等。 這種帶註釋的數據形式在更好地訓練虛擬助手和聊天機器人方面很有意義。
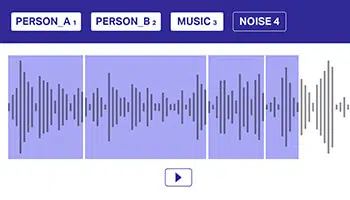
多標籤
註解
通過使用多個標籤來註釋音頻數據對於幫助模型區分重疊的音頻源很重要。 在這種方法中,音頻數據集可能屬於一個或多個類,需要明確地傳達給模型以進行更好的決策。

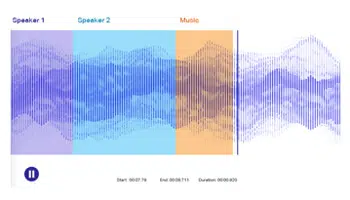
說話人分類
它涉及將輸入音頻文件拆分為與各個揚聲器相關的同質片段。 分類意味著識別揚聲器邊界並將音頻文件分組為段以確定不同揚聲器的數量。 此過程有助於自動化對話分析和呼叫中心對話、醫療和法律對話以及會議的轉錄。
音標
與將音頻轉換為單詞序列的常規轉錄不同,語音轉錄會記錄單詞的發音方式,並使用音標在視覺上表示聲音。 音標可以更容易地註意到幾種方言中同一語言的發音差異。

員工
專門和訓練有素的團隊:
- 30,000 多名數據創建、標籤和 QA 協作者
- 有資質的項目管理團隊
- 經驗豐富的產品開發團隊
- 人才庫採購和入職團隊

過程
通過以下方式確保最高的流程效率:
- 穩健的 6 Sigma Stage-Gate 工藝
- 一個由 6 Sigma 黑帶組成的專門團隊——關鍵流程負責人和質量合規
- 持續改進和反饋循環

平台
獲得專利的平台具有以下優勢:
- 基於網絡的端到端平台
- 無可挑剔的品質
- 更快的 TAT
- 無縫交付
員工
專門和訓練有素的團隊:
- 30,000 多名數據創建、標籤和 QA 協作者
- 有資質的項目管理團隊
- 經驗豐富的產品開發團隊
- 人才庫採購和入職團隊
過程
通過以下方式確保最高的流程效率:
- 穩健的 6 Sigma Stage-Gate 工藝
- 一個由 6 Sigma 黑帶組成的專門團隊——關鍵流程負責人和質量合規
- 持續改進和反饋循環
平台
獲得專利的平台具有以下優勢:
- 基於網絡的端到端平台
- 無可挑剔的品質
- 更快的 TAT
- 無縫交付

文字註解
服務
我們專注於通過註釋詳盡的數據集、使用實體註釋、文本分類、情感註釋和其他相關工具來準備文本數據訓練。

圖像註釋
服務
我們以標記、分割圖像數據集來訓練計算機視覺模型而自豪。 一些相關技術包括邊界識別和圖像分類。

視頻註釋
服務
Shaip 提供用於訓練計算機視覺模型的高端視頻標記服務。 目的是使數據集可用於模式識別、對象檢測等工具。


