
人工智能促進了與計算系統的類人交互,而機器學習則允許這些機器通過每次交互學習模仿人類智能。 但是,是什麼為這些高度先進的 ML 和 AI 工具提供動力呢? 數據註釋。
數據是為機器學習算法提供動力的原材料——你使用的數據越多,人工智能產品就會越好。 雖然訪問大量數據至關重要,但確保對它們進行準確註釋以產生可行結果同樣重要。 數據註釋是先進、可靠和準確的 ML 算法性能背後的數據動力。
數據標註在人工智能訓練中的作用
數據註釋在 ML 訓練和 AI 項目的整體成功中起著關鍵作用。 它有助於識別特定的圖像、數據、目標和視頻,並對它們進行標記,使機器更容易識別模式和對數據進行分類。 這是一項以人為主導的任務,可訓練 ML 模型做出準確的預測。
如果數據標註不准確,機器學習算法就無法輕易地將屬性與對象關聯起來。
帶註釋的訓練數據對 AI 系統的重要性
數據註釋使 ML 模型能夠準確運行。 數據註釋的準確性和精確度與 AI 項目的成功之間存在著無可爭辯的聯繫。
到 119 年,全球人工智能市場價值預計將達到 2022 億美元,預計將達到 由1,597支付$ 2030十億,在此期間以 38% 的複合年增長率增長。 雖然整個 AI 項目會經歷幾個關鍵步驟,但數據標註階段是您的項目處於最重要的階段。
為了數據而收集數據不會對您的項目有太大幫助。 您需要大量高質量的相關數據才能成功實施 AI 項目。 在 ML 項目開發中,大約 80% 的時間花在與數據相關的任務上,例如標記、清理、聚合、識別、擴充和註釋。
數據註釋是人類比計算機具有優勢的一個領域,因為我們天生就有能力破譯意圖、排除歧義並對不確定信息進行分類。
為什麼數據註釋很重要?
您的人工智能解決方案的價值和可信度在很大程度上取決於用於模型訓練的數據輸入的質量。
機器不能像我們一樣處理圖像; 他們需要接受培訓以通過培訓識別模式。 由於機器學習模型迎合了廣泛的應用——醫療保健和自動駕駛汽車等關鍵解決方案——數據註釋中的任何錯誤都可能產生危險的影響。
數據註釋可確保您的 AI 解決方案發揮其全部功能。 訓練 ML 模型以通過模式和相關性準確解釋其環境、做出預測並採取必要的行動需要高度分類和註釋 訓練數據. 註釋通過標記、轉錄和標記數據集中的關鍵特徵向 ML 模型顯示所需的預測。
監督學習
在我們深入研究數據註釋之前,讓我們通過有監督和無監督學習來闡明數據註釋。
機器學習監督機器學習的一個子類別表示在標記良好的數據集的幫助下進行 AI 模型訓練。 在監督學習方法中,一些數據已經被準確地標記和註釋。 ML 模型在接觸新數據時會利用訓練數據根據標記數據做出準確的預測。
例如,ML 模型是在裝滿不同類型衣服的櫥櫃上訓練的。 訓練的第一步是使用每件衣服的特性和屬性,用不同類型的衣服訓練模型。 訓練結束後,機器將能夠通過應用其先前的知識或訓練來識別不同的衣服。 監督學習可以分為分類(基於類別)和回歸(基於真實值)。
數據註釋如何影響人工智能係統的性能
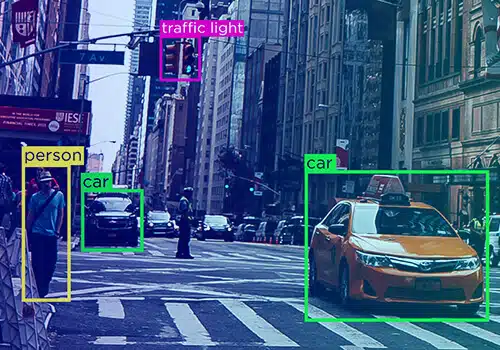 數據從來都不是一個單一的實體——它有不同的形式——文本、視頻和圖像。 不用說,數據註釋有不同的形式。
數據從來都不是一個單一的實體——它有不同的形式——文本、視頻和圖像。 不用說,數據註釋有不同的形式。
為了讓機器理解並準確識別不同的實體,強調命名實體標記的質量很重要。 標記和註釋中的一個錯誤,ML 無法區分亞馬遜——電子商務商店、河流或鸚鵡。
此外,數據註釋有助於機器識別微妙的意圖——這是人類天生具備的品質。 我們的交流方式不同,人類既能理解明確表達的想法,也能理解隱含的信息。 例如,社交媒體回复或評論可能是正面的也可能是負面的,ML 應該能夠理解這兩者。 '好地方。 將再次訪問。 這是一個積極的短語,而“它曾經是一個多麼棒的地方!” 我們曾經很喜歡這個地方! 是負的,人工註釋可以使這個過程更容易。

數據註釋中的挑戰以及如何克服這些挑戰
數據註釋的兩個主要挑戰是成本和準確性。
需要高度準確的數據: AI 和 ML 項目的命運取決於註釋數據的質量。 ML 和 AI 模型必須始終如一地提供分類良好的數據,這些數據可以訓練模型識別變量之間的相關性。
對大量數據的需求: 所有 ML 和 AI 模型都在大型數據集上茁壯成長——單個 ML 項目至少需要數千個標記項。
資源需求: 人工智能項目在成本、時間和勞動力方面都依賴於資源。 如果沒有其中任何一個,您的數據註釋項目質量可能會失控。
[另請閱讀: 機器學習的視頻註釋 ]
數據標註的最佳實踐
數據標註的價值體現在它對 AI 項目成果的影響上。 如果您用來訓練 ML 模型的數據集充斥著不一致、有偏見、不平衡或損壞的情況,那麼您的 AI 解決方案可能會失敗。 此外,如果標籤錯誤,註釋不一致,那麼人工智能解決方案也會帶來不准確的預測。 那麼,數據標註的最佳實踐是什麼?
高效和有效數據註釋的技巧
- 確保您創建的數據標籤是特定的並與項目需求一致,但又足夠通用以適應所有可能的變化。
- 註釋訓練機器學習模型所需的大量數據。 您註釋的數據越多,模型訓練的結果就越好。
- 數據註釋指南在建立質量標準和確保整個項目和多個註釋者之間的一致性方面大有幫助。
- 由於數據註釋可能成本高昂且依賴人力,因此從服務提供商處檢查預先標記的數據集是有意義的。
- 為了幫助進行準確的數據註釋和培訓,引入人在循環中的效率以帶來多樣性和處理關鍵案例以及註釋軟件的功能。
- 通過測試註釋器的質量合規性、準確性和一致性來確定質量的優先級。
註釋過程中質量控制的重要性
 高質量的數據註釋是高性能 AI 解決方案的命脈。 註釋良好的數據集可幫助 AI 系統無可挑剔地運行,即使在混亂的環境中也是如此。 同樣,反之亦然。 充滿註釋不准確的數據集將拋出不一致的解決方案。
高質量的數據註釋是高性能 AI 解決方案的命脈。 註釋良好的數據集可幫助 AI 系統無可挑剔地運行,即使在混亂的環境中也是如此。 同樣,反之亦然。 充滿註釋不准確的數據集將拋出不一致的解決方案。
因此,圖像、視頻標籤和註釋過程中的質量控制在 AI 結果中起著重要作用。 然而,對於小型和大型公司而言,在整個註釋過程中保持高質量的控制標準是一項挑戰。 對各種類型的註釋工具和多樣化的註釋勞動力的依賴可能難以評估和保持質量一致性。
保持分佈式或遠程工作數據註釋器的質量很困難,尤其是對於那些不熟悉所需標準的人來說。 此外,故障排除或錯誤糾正可能需要時間,因為需要在分散的員工隊伍中進行識別。
解決方案是培訓註釋者,讓主管參與,或者讓多個數據註釋者調查和審查同行的數據集註釋準確性。 最後,定期測試註釋者對標準的了解。
註釋者的作用以及如何為您的數據選擇正確的註釋者
人類註釋者掌握著 AI 項目成功的關鍵。 數據註釋器可確保數據準確、一致且可靠地進行註釋,因為它們可以提供上下文、理解意圖並為數據中的基本事實奠定基礎。
一些數據在自動化解決方案的幫助下被人工或自動註釋,具有相當的可靠性。 例如,您可以從谷歌下載數十萬張房屋圖像並將它們製成數據集。 但是,數據集的準確性只能在模型開始執行後才能可靠地確定。
自動化可能會使事情變得更容易和更快,但不可否認的是,準確性較低。 另一方面,人工註釋器可能更慢且成本更高,但它們更準確。
人類數據註釋者可以根據他們的主題專業知識、先天知識和特定培訓對數據進行註釋和分類。 數據註釋器建立準確性、精確性和一致性。
[另請閱讀: 數據註釋初學者指南:技巧和最佳實踐 ]
結論
要創建高性能的 AI 項目,您需要高質量的帶註釋訓練數據。 雖然始終如一地獲取註釋良好的數據可能會耗費時間和資源——即使對於大型企業也是如此——但解決方案在於尋求像 Shaip 這樣的成熟數據註釋服務提供商的服務。 在 Shaip,我們通過數據註釋專家服務滿足市場和客戶需求,幫助您擴展 AI 功能。


